

株式会社 Polyscape 代表取締役の島田です。自分は代表でありながら、AIエンジニアリングのプロフェッショナルとして、これまで多くのエージェント開発やRAGといった対話型システムの開発を手掛けてきました。
今回は、LLMを用いた対話型エージェントや対話式のRAGシステムといった、対話型AIシステムの要件定義について解説していきたいと思います。以下のような方を想定読者としています。
- 受託開発でエージェントやRAGシステムを作ることになったが、どのように要件定義すればいいかわからないプロジェクトマネージャーの方
- 受託開発でエージェントやRAGシステムの要件定義書を渡されたが、どう設計をしたらいいかわからないエンジニアの方
- 自社開発でエージェントやRAGシステムを作ることになったが、どこからはじめたらいいかわからないプロダクトマネージャやエンジニアの方
- 対話型AIシステムの開発は、通常のITシステム開発と違う
- 対話システムの2タイプ
- 要件定義においての項目テンプレート
- 基本設計について
- 典型的な開発計画と金額
- 「RAGが動く」と「RAGがビジネス上使える」の大きなギャップ
対話型AIシステムの開発は、通常のITシステム開発と違う
対話型AIシステムの開発は通常のITシステム開発と大きく違います。通常のITシステム開発は、たくさんのモジュールで構成されており、モジュールのインプットアウトプットを規定することで システムの仕様が定義できます。モジュールのインプットアウトプットは基本的に形式が固定されており モジュールはたくさんあるものの、パターンは有限です。
一方で、エージェントのような対話型システムは主要なモジュールは基本的には対話であり、数が限られているものの、そこに対して実質的に無限のインプット、アウトプットが想定されます。
そのため、特定のインプットに対してアウトプットの要件を定義し、それに対して正しく期待通りも動作していると確認できたとしても、顧客やエンドユーザーにより要件に定義されていないインプットが入力され想定外の挙動が発生すれば、それは不具合と認定されてしまいます。
このように、通常のITシステムの常識がまかり通らない流動的なものなので、要件定義や開発のアプローチは従来と違った考え方が求められます。
対話システムの2タイプ
基本的にAIを用いた対話システムには2通りあると考えており、それぞれのパターンや設計の仕方を解説します。
シナリオ型
シナリオ型は特定のシナリオに沿って会話するようなタイプの対話システムです。例えば、ヒアリング項目が決まっており、何回か質問を繰り返して、その後診断や回答を一気に提示するといったパターンの対応システムに有効です。対話の内容などによって分岐が発生したりします。
弊社が開発を担当したAI調香コンシェルジュ「八峰コロン」などもこちらのシナリオ型の対話システムに該当します。

半年で実現した「AI調香師」開発。Polyscapeが金熊香水の事業課題解決に貢献した伴走術
株式会社ピノーレは、2017年12月、長野県諏訪郡富士見町・八ヶ岳南麓の自然豊かな地に、香水・香粧品の研究所を…
シネリオ型は基本的にフローチャートで流れを定義することができます。以下は一部ですが、年齢や性別を質問をしてから診断をするエージェントフローチャートの例です。シナリオ型を定義する場合、一定シナリオにそぐわない回答が発生した場合、どのように処理するかも期待していかなければいけません。そういった場合元のフローに戻るのか、例外的なフローに分岐していくかなどは、設計やデザイン次第となります。

エージェント型
エージェント型は最近増えてきた対応システムの形式です。シナリオ型のような特定のシナリオはなく、エージェントと自由にフリートークすることができる対話システムの形式です。エージェントは様々な道具箱である「ツール」を持っており、ユーザーのリクエストに応じて適切なツールを呼び出して返答を生成します。複雑なタスクの場合、ツールを呼び出す変わりに、更にツールをぶらさげた「エージェント」を呼び出し、入れ子構造となっていくマルチエージェント形式も存在します。
Difyやn8nやLangchainではエージェントの構造は左から右に流れるノードとエッジで表現されるため、これを簡略化した図でエージェントの設計を表現することが多い印象です。弊社ではこれをオーケストレーション・フロー図とよんでいます。ワークフローダイアグラムといった呼び方もありますが、Difyなどをはじめ複数のタスクを組み合わせ、調和させ、全体として意味ある動きにすることから、エージェントの動きをオーケストレーションといった呼び方で呼ぶことから、このような名称で呼んでいます。
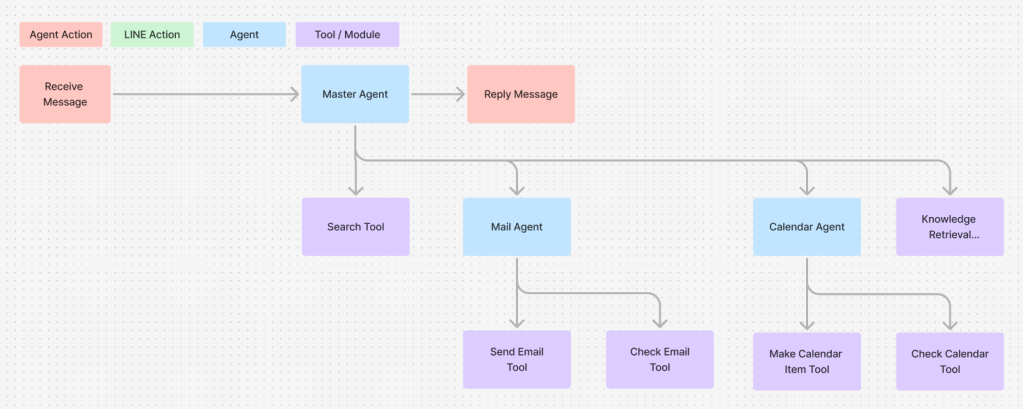
以下は、オーケストレーションフロー図の例です。カレンダーやメールを呼んだり、ユーザーからの質問に検索をして答えたり、Knowledge Retrieval(いわゆるRAG)を使って答えたりする秘書エージェントを表現しています。
ユーザーのメッセージを受けて、それをマスターエージェントが解釈したうえで、自分に紐づいている適切なツールを呼びます。今回の例ではメールエージェント、カレンダーエージェントという部分が更にエージェントとなっており、そこからメールの受信か送信か、カレンダーの読み込みか書き込みかというタスクによって呼ぶツールが細分化していきます。検索かKnowledgeRetrieval(RAG)かという部分もエージェントに判断され、ツールとして呼び出されます
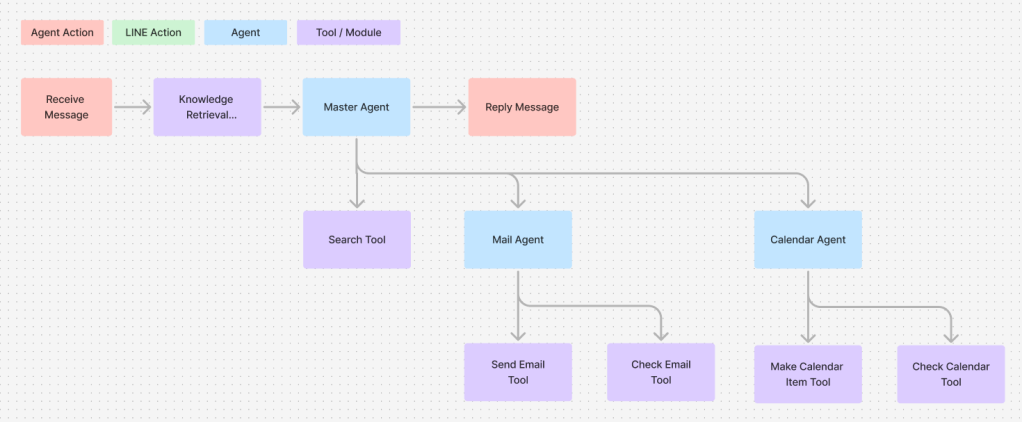
このエージェントには、以下のような代替設計も存在します。KnowledgeRetrieval(RAG)をツールとしてではなく、最初の段階でエージェントに入るクエリの前で呼んでしまうというやり方です。基本的には上記の設計が一般的ですが、毎回必ずRAGが呼ばれるので「エージェントの判断でRAGが呼ばれずハルシネーションにつながる」といったことが回避できるほか、RAGの知識によって呼ばれるツールが変わるシチュエーションに有効です。
こちらのデメリットは「こんにちは」といったRAGが必要ない会話でもラグが呼ばれてしまい、場合によってはコンテキストと外れた回答をしたり時間がかかってしまう可能性があります。
このように同じ働きをするエージェントも複数の設計の仕方があります。それぞれの設計によってデメリットメリットがあるので、用途によって適切な設計を考える力が現代のAIエンジニアには求められます。
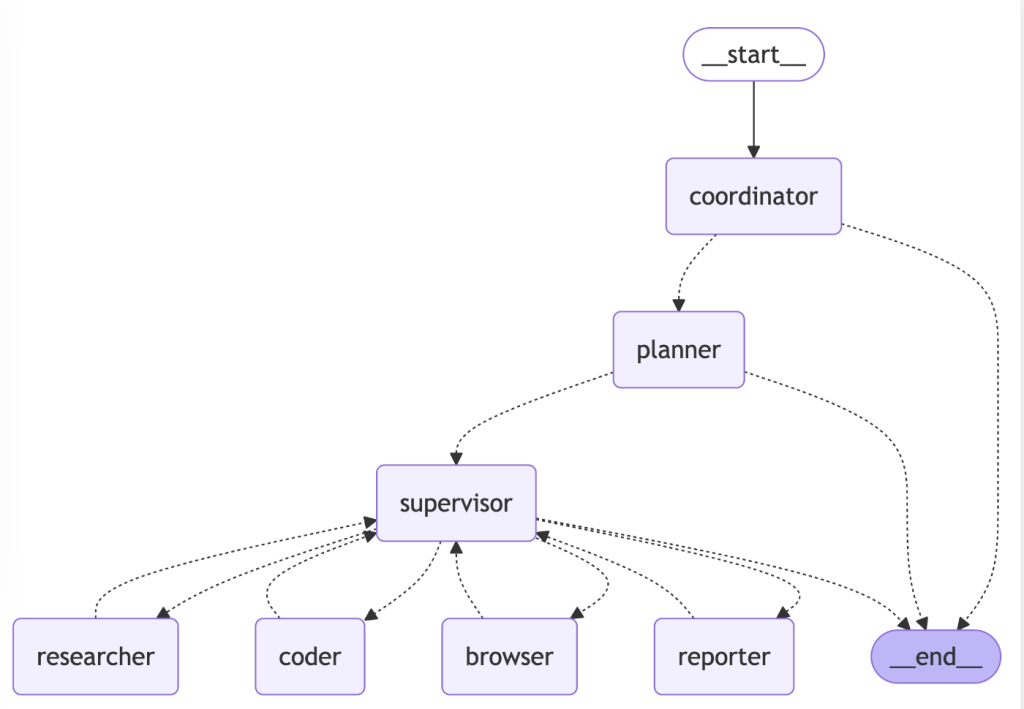
OpenManus や LangManusなどに代表されるマルチエージェントシステムでは、以下のようなエージェントダイアグラムも用いられます。これではないといけないという決まった書式はないので、開発者やクライアントに分かりやすい 書式でエージェントの設計を表現しましょう。
要件定義においての項目テンプレート
1. 目的背景
この項目は必須ではありませんが、開発する対話システムの目的や開発しようと思った背景を書くことで、この要件定義書を見て開発する開発者がより上位のコンテキストを理解することができます。
2. ユーザーストーリー
ユーザーストーリーとは、プロダクト開発において使われる「ユーザー視点で書かれた要件」のことです。
「As a(誰として) I want(何をしたい) So that(なぜ、それでどんな価値があるか)」
という簡潔な文章で表現されます。ユーザーストーリーは、システムの機能説明ではなく、ユーザーが何をしたいかということを中心として書く必要があります。以下は、メールを返してくれるメールエージェントのユーザーストーリーの例です:
ユーザーストーリー 1:メール受信
- As a 忙しいビジネスマン
- I want メールエージェントが新着メールを自動で確認してくれる
- So that 数あるプロモーションメールの中から返信が必要なメールを取り出してくれることで、メールボックスに向き合う時間やマインドシェアがセーブされる
ユーザーストーリー 2:返信候補の生成
- As a 忙しいビジネスマン
- I want メールの内容に応じた返信文を自動生成してほしい
- So that 下書きを修正するだけで済む
ユーザーストーリー 3:送信と確認
- As a 忙しいビジネスマン
- I want 生成されたメールを確認して送信できるようにしたい
- So that AIが生成した文章をそのまま送るのは怖いので、間違いのない内容を相手に送れる
ユーザーストーリーは仕様を事前に定義しにくい対話システムだからこそ効果を発揮します。テストをしていくと無限にエッジケースのようなテストケースが出現するので「ここまで対応する必要ある?」ということを議論するうえで、ユーザーストーリーに立ち帰って、これはいる・これはいらないという議論をすることができることが、ユーザーストーリーの意義と言えます。
受託開発の場合は、ユーザーストーリーのスコープを決めることにより、「これは今回のユーザーストーリーとは関係が無いので今回は対応しません、次のフェーズでやりましょう」といったスコーピングにも役立ちます。
3. 機能要件
3.1 対話仕様
対話システムなので、まずは対話に関する仕様を提示します。これは後続のエンジニアに対してプロンプトを定義するのに役立ちます。以下のような項目で定義するとよいでしょう。
- 期待される対応:おすすめレストランを聞かれた際にレコメンドをする、製品についての質問が来たら真摯に対応する等、ユーザーストーリーを達成するために期待されるベースの対応を記述します
- 口調や設定:多様システムがどのような言葉遣いを使うか 敬語なのか、タメ口なのか、自分をなんと名乗るか、絵文字を使用するか etc
- 不適切会話に対する対応方針:成人向けのコンテンツ生成やプロンプトインジェクションなどが行われた際にどのような振る舞いをするか
- 回答ができなかった場合の案内:FAQシステムでは、しばしばRAGに情報がなく回答ができない場合があります。このような時に無理やりに回答させようとするとハルシネーションが発生するので ビジネスでの対話システムに関しては回答ができない場合は「回答ができませんでした」と答えるのがおすすめです。このような場合に連絡先を表示するなりお問合せ先を表示するか、といった部分を記載します
3.2 ツール(タスク実行)仕様
エージェントがより複雑なタスクを実行する場合、ツールやエージェントをコールする必要があります。このセクションではツールやコールの仕様を詳細に定義します。ツールの要件定義の型はありませんが、「Call Conditions(いつ呼ぶか)」「Behavior(挙動)」「I/O(入出力)」で定義すると、実装する側人にとっての明瞭性が上がります。
例えば秘書のエージェントでは、メールに関する2つのツールを以下のように定義しています。
メール送信ツール(SendEmailTool)
- Call Conditions(いつ呼ぶか):「メールを書いて」という指示では本文を作成するのみでメールの送信は行わない。送信前に必ずユーザーに確認を求める。送信をする際は、ユーザ意図が「送って」「返信して」「展開して送付」等で、本文案が確定しているときのみ。
- Behavior(挙動):すでに認証が済んだユーザーのGmailアカウントからインプットに指定されたメールアドレス・件名、本文で送信先アドレスに対しメールを送信する。返信先メールIDが指定されている際はスレッドにリプライを行う
- I/O(入出力)
- インプット:送信先メールアドレス(複数指定可)、件名、本文、返信先メールID
- アウトプット:成功時はメール本文をエージェントに返す。配送不能(5xx)時は再試行、恒久エラー(アドレス不正等)は即時失敗。
チェックメールツール(CheckEmailTool)
- Call Conditions(いつ呼ぶか):「新着確認」「未読だけ見せて」「最新N件を要約」等の指示時。会議直前の関連メール収集や、返信候補作成の前処理として。
- Behavior(挙動):すでに認証が済んだユーザーのGmailアカウントから未読のメールN件(インプットで指定)を取得し、返信の必要がありそうなものをJSONで返しつつ、CheckNeededというGmailラベルを付与する。それ以外のものは未読状状態を解除する。
- I/O(入出力)
- インプット:チェック件数
- アウトプット:返信の必要がありそうなメールのリストをJSON化したもの
3.3 RAG仕様
現在のAIを用いた対応システムには、RAGなどのKnowledge Retrievalが必ずと言っていいほど組み込まれます。そのモデルではエージェントに答えさせたい文脈やナレッジが必ずしも含まれているとは限らないので、そういったものを外部の知識データベースで補うという手法です。
基本的に要件定義に書かれるべきものとしては、KnowledgeBaseの情報ソースです。例えば以下はとあるシステム開発における仕様を確認できるエージェントのRAGデータの例です。
- ◯◯システム 要件定義書
- ◯◯システム 基本設計書
- 2025/6/1 ~ 2025/12/31 のA社とB社の商談議事録
- ◯◯社 WEBサイト
WEBサイトは最初に入れた情報を使うのか、常にアップデートをし続けるのか等も論点になります。また、暗黙的に常にウェブサイトの情報をアップデートすることを期待されていることもあるので、そうでない場合は、しっかりといつ時点のデータでアップデートはしないと記載することがいいでしょう。
また、RAGを利用した際に、ソースとなったドキュメントの出典を表示したいという要求も「RAGあるある」な要求なので、そのような点に対応するかどうかも記載しておくといいでしょう。
RAGを実際に構築される際の設計として、以下のようなパラメータや検索方式も決めていく必要があります。
- 検索やインデックス手法(Keyword SearchかSemanticかなど)
- ナレッジ抽出がTOP−K方式からしきい値方式か
- ドキュメントを取り込んでナレッジベースを作成する際のチャンクの長さやオーバーラップサイズなど
- ソースのURLやメタデータ
これは要件定義というよりは基本設計書に書かれる内容であり、RAGを担当するエンジニアが決定します。
3.4 管理機能
対話に集中していると忘れがちになりますが、エージェントとの会話ログが、どのような形で確認できるのかをあらかじめ要件に含めることを忘れてはいけません。
- ログの確認方法
- ログに表示されている項目
- 利用統計などの確認方法
以上のような項目がわかるように記されている必要があります これは必ずしもダッシュボードのような機能としてではなく、CSVにしてエクスポートする、Difyのようなマネージドサービスのデフォルトログを使うといった方法もあるのでそういった部分を事前に定義しておくと良いでしょう。
4. 非機能要件
4.1 対応言語
日本語、英語など、エージェントの対応言語を記載します。
エージェントの対応言語は馬鹿にできません。「LLMだから多言語対応でしょ」という考え方は間違いではないですが、例えばエラーメッセージやオープニングメッセージなどの定型文があった場合、多言語対応の分だけそれを用意するコストが発生する可能性があったり、設計を簡略化できなかったりするので、基本的に不要な言語は仕様の段階から外しておくことを推奨します。
また、多言語対応をする場合の注意点として、英語を要件として入れる場合、「英語で喋っているのに日本語で返ってきた」といった部分も不具合扱いになります(こういったことが “常に”ではなくて、特定のクエリやエッジケースで発生するのがエージェント開発の怖いところです)。現在のAIはシステムプロンプトに言語が引っ張られたりする傾向があるので、どこかに日本語が潜んでいるだけで英語で返せないといった状況が発生したりします。多言語をスコープとすることはそういったことにコミットする必要があるということです。
多言語を扱う場合でも、メイン言語を決めておくことを推奨します。前述の通り、現在のAIはシステムプロンプトの言語に引っ張られるので、メイン言語でシステムプロンプトを書くのが合理的で、それを要件定義段階から決めておけると良いです。
4.2 性能要件
4.2.1 応答時間
対話システムで大きな論点となるのが応答時間です。通常のLLMの返答だけで言うとコンテキストの長さにはよりますがせいぜい3-6秒で回答はできると期待されますが、ツールのコールが入ったり、他エージェントのコールが入ったりする場合は、基本的にそれだけ時間がかかるので、20-30秒、もしくは1分とかかるケースも考えられます。
こちらは本当にやらせる内容や設計次第ですが、受託開発の場合はそういった部分もあらかじめ顧客と期待値調整をする必要があります。「通常会話 3-4秒目安、検索発生時は30秒程度の応答時間を目安とする。ただし、『検索中』といった表記などのプログレスメッセージは少なくとも2-3秒以内に返す」といった形で定義しておくと良いかもしれません。ただ、こちらも入れられるインプット次第 になるので、この場合もコミットする条件というよりはあくまで目安という握りをしておく必要があります。
エージェント開発においては通常の ChatGPTよりもシステムプロンプトが多めになるので、(もちろん 出力トークン数の影響は大きいですが)通常のAIの感覚よりも応答時間が長くなるというような感覚を持っておいた方が安全です。
4.2.2 回答精度
応答時間と並んで論点となるのが、回答精度です。対話システムの回答精度は定義するのが非常に難しいです。クラス識別などと違って明確に何%という精度が出せません。また、LLMを使っている以上、言語モデルというものの定義と性質上ハルシネーションは絶対にゼロにはできません。回答精度の定義について明確な回答は我々も持っていませんが、エージェントシステムとしてどのレベルのハルシネーションを許容し、どのレベルを許容しないかという基準に関しては一定定めておけると良いと思います。
例えば、レストラン施設のレコメンドエージェントの場合、以下のような基準で定義ができるかもしれません。
- 架空の施設のレコメンド:許容しない
- 存在する施設についての属性情報の捏造:許容しない
- (例)営業時間が間違っている 等
- レコメンドのエラー:許容(ベストエフォート)
- (例)焼き肉を食べたい、と言われたときにシェラスコの店が出てくる 等
- レコメンドの文脈に関係のない、LLMレベルのハルシネーション:許容(ベストエフォート)
AIに関してのリテラシーは様々で、「ハルシネーションが起きないAIシステムを作ってください」とお願いされることはありますが、現実的ではない部分があります。このようなことがいざ納品時に発覚するのではなく、要件定義時にお伝えをして、顧客との適切な落とし所を開発前に見つけていくということが対話システムの受託開発では非常に重要となります。
余談としてハルシネーションが全く許されない 仕組みにおいては、RAGではなく検索システム(クエリをAIが考えてクエリに引っかかるものを使う)や、そもそもAIを生成使わない(もともと存在する記事をリンクするだけ等)というアプローチが考えられます。
4.3 UX要件
UX要件とは、対話の内容とは関係のない、ローディングメッセージなどのエフェクトに関する要件です。対応システムとしては非機能容器に分類しています。
- ローディングエフェクト
- Tool呼び出し時のプログレスメッセージ
- オープニングメッセージ
などが該当します。Tool呼び出し時のプログレスメッセージとは、ChatGPTではおなじみの「考えています」「検索しています」などのエージェントが今何をしているかを示すメッセージです。
ユーザーは発話を送ったのにレスポンスがなかったりすると不安になるので、UXとしては意外と大事です。検索時などは時間がかかる場合がありますが、「ローディングエフェクトを出すだけ」なのか「検索中ですというメッセージを出す」のか「検索している媒体やソースを表示する」のかによって 構成や実装のアプローチが変わるので こういった部分にも求められる要件を明確化する必要があります。
4.4 セキュリティ要件
こちらに関しては通信方式や、LLMの利用ポリシー(オープンモデルは使わない、等)などを書いておくと良いと思いますが、従来の要件定義にも共通している要素なので詳細の説明は割愛します。
5. 想定質問
エージェントの要件定義は抽象的な記述だけでは形が作られないので、具体的な質問に関してどのように回答してほしいか、ということをあらかじめ想定質問回答という形で記述することをお勧めします。想定質問に対し想定回答を書いておける形がベストではありますが、AIの回答は詳細まで制御できないため、想定回答そのものを書くというよりは、この質問に対し何ができていればOKなのか、という適合基準を定めておくことをお勧めします。以下はオススメ施設レコメンドアプリの例の想定質問の例です。
- 想定質問:「アプリのダウンロードの仕方を教えて」
- 適合基準:FAQの情報に即したアプリのダウンロード方法が案内できている
- 想定質問:「恵比寿のオススメのバーを教えて」
- 適合基準:施設情報のRAGから恵比寿のバーを検索し、RAGの情報を正しく回答できる
- 想定質問:「今日の天気を教えて」
- 適合基準:検索を行って、今日の正しい天気を回答することができる
想定質問回答を書いておくメリットとして、こちらが対応システムを開発した後のテストケースとしてワークするという点があります。通常のシステム開発では、「新規追加ボタンを押すと新しく新規◯◯が追加され、デフォルト値が入っている」などといったテストケースを書いてテストしますが、それに当たるものがこの想定質問です。
開発をするエンジニアもどんな質問に対して答えればいいのかということがイメージできた方が実装の方針が湧きます。こちらはスプレッドシートやテーブルなどに別途記載して、想定質問一つ一つにテストが通ったか、ということを記載していくと良いでしょう。
基本設計について
上記は要件定義書であり、一部設計に関しての記載を含んでいますが、あくまでユーザーストーリーを実現するプロダクト(エージェント)はなにか、というWHATを記載したものになり、プロジェクトマネージャーやプロダクトマネージャーの責任範囲になります。
これに続く工程としては基本設計、詳細設計、というものがあります。これはWHATをどのように実現するかというHOWを記したもので、一般にはリードエンジニアやエンジニアマネージャの責任範囲となります。対話システムの場合、そこまで複雑化しなければ要件定義書に基本設計を含める形でも問題はないと思いますが、もし基本設計書を提出したりする必要がある場合は以下のような項目を含めると良いと思います。
- 上記に言及したフローチャート図や、オーケストレーションフロー図
- 使う言語モデルはなにか なぜそれを使ったか
- 対話要件を満たすためのプロンプトはなにか
- ツールの詳細設計
- RAGに関しての設定、パラメータや検索手法、使うVectorDBの種類など
- セキュリティを担保するための仕組みや構造
今回は要件定義が主軸のため、詳細は割愛します。
典型的な開発計画と金額
対話システムのうち、エージェント開発の典型的な開発計画として、ツールの多さや求められているRAGの精度などにはよりますが、通常ベースとなるものは一人のエンジニアを入れて3ヶ月、そこに追加機能(音声認識なり、WEBサービスのUIなり、既存システムとの繋ぎ込み)が入るとプラスアルファで伸びるといった印象です。予算次第で、機能をシンプルにして2ヶ月に圧縮したりすることは可能です。
以下は弊社でエージェントを受託開発をする際の典型的なスケジュール例です。比較的余裕を持って引いている例ではありますので、多少の調整は効きます。
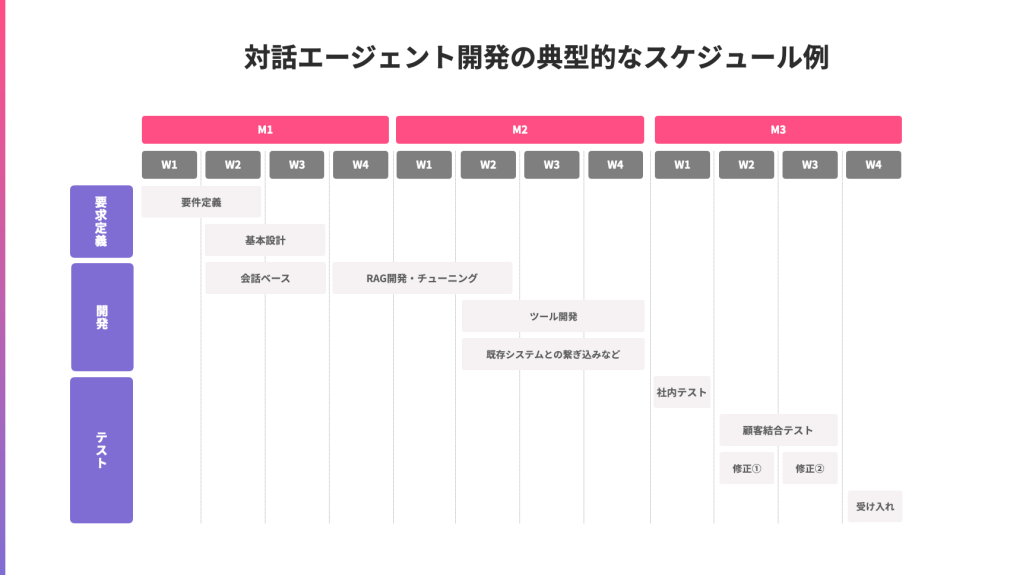
計画の中で最もポイントとなる点が、「最後の1ヶ月はほぼすべてテストとその修正に当てる」ということです。工期の3分の1がテスト期間となるのは通常の開発からすると長い印象ですが、対応システムの場合はこの長いテスト期間が非常に重要です。
上記のように要件定義をしても結局顧客の本当の要求が要件定義できるとは限らず、「納品前のテストで、顧客が本当にしたかったことやクオリティラインが初めて明確になる」ということが起きやすいのがエージェント開発です。基本的には小さなエージェントでも納品の3週間前から顧客を巻き込んだテストを開始します。基本的には1週間づつ、3回行います。最後のは受け入れテストですので、それまでには2回のテストで2回の修正を入れて、要望に近づけていきます。冒頭で書いたように、原理的に対話システムに関しては最初での要件定義が不可能なので、長いテストでカバーするというのが現実的なアプローチとなります。したがって、開発自体は2ヶ月で終わらせないといけません。
金額としては、通常の小規模なものだと540~660万円、スコープを調整して2ヶ月でやれば380万、もっと機能を乗せる場合はそれ以上、といったところでしょうか。規模や追加機能次第ではいくらでも大きくなりますが、基本的なシステムは上記のようなイメージかと思います。逆にそれ以下でやろうとする場合、システム自体はできますが、精度が犠牲になるため、ビジネス上実際に使えるものにはならない可能性が高いです。
「RAGが動く」と「RAGがビジネス上使える」の大きなギャップ
Difyなどサービスにより、誰でも簡単にRAG構築ができるようになり、エージェント開発や、RAG構築は一般化しました。とりあえずナレッジを入れて回答をするRAGエージェントは1時間もかからずに作れますが、問題は、「実際にビジネスで使えるようになる」という水準は、そのラインに比べて非常に高いということです。
社内システムであれば比較的そのラインは低いですが、特にtoCに向けて使われるようなサービスでは、サービスのブランドや信頼性にも関わる他、売上も左右するので、エッジケースに対してもハルシネーションが許されないケースが多いでしょう。そのようなケースを一つ一つ潰していかないといけないのが、RAGのブラッシュラップです。
RAGをブラッシュアップするアプローチは、
- Chunkサイズの調整
- Chunk OverlapなどのChunkのパラメータ調整
- Chunkやドキュメントに対するメタデータの付与
- ナレッジとして取り込むファイルのデータクレンジングや整形
- 検索方式・インデックス方式の変更
- Rerankモデルの調整
- しきい値やTop-Kなどの検索パラメータ設定
- RAGを取り込む設計の変更(ツール化するか前段で取り込むか等)
- RAGに対するクエリの変更
- embeddingモデルの変更
- VectorDBの変更
- マスターエージェントのプロンプト
など、いろいろなやり方が考えられます。こういったことに関してはまた詳細の解説記事を出したいと考えていますが、これらの調整は完全にAIエンジニアの専門知識となるので、受注側も発注側も「データを取り込んだらRAGができるんでしょ?」と甘くみてしまうのは非常に危険です。
手前味噌にはなりますが、弊社では、私をはじめAIやプロダクト開発に関してのプロフェッショナルが揃っていますので、このような専門知識の伴うRAGの調整やビジネスで使える対話エージェントの開発ではご相談いただければと思います!
ここまで読んでいただき、ありがとうございました。
