

最近、社内でDifyを使って様々なバックオフィスの業務の自動化を図るプロジェクトが増えてきています。今回はその第二弾として、Dify ✕ Notion ✕ Slackで作る社内用案件稼働管理ツール、「稼働管理ちゃん」の作り方についてご紹介させてください。
開発背景
Polyscapeでは受託案件の管理をNotionで行っています。
Salesforceの思想をお借りして、大きく分けると3つのNotion DBで管理をしています:
- AI/DX事業 顧客管理ボード:Salesforceでいう「取引先責任者」という概念と似ており、受注前の顧客から継続受注・取引終了した顧客までまとめて管理をしています。
- AI/DX事業 Dashboard:Salesforceでいう「商談」という概念と似ており、契約書・発注書をベースに、案件を受託した各お客様との案件の売上や手続きのステータスなどをまとめて管理をしています。
※更に請求書を分けたりまとめたりもするので、Notion上ではこちらのDBをサブアイテムをONにして、複数請求がある場合はサブアイテムにて管理をしています。 - 案件稼働管理:各案件にアサインされたメンターの稼働工数を管理するテーブルになります。稼働管理ツールはたくさんありますが、ZAC(キャプチャをご参照)のようなイメージが一般的でしょう。
受託開発において、原価(社員の工数)管理がとても重要で、それをリアルタイムに把握する必要があります。
かといって、ガチガチやりすぎると、社員を監視するような仕組みになりがちで自由な風土を失うほか、かえって効率が悪くなるので、ほどよい管理が望ましいです。
そんな中で、我々がこだわっていたのは以下の点です:
- 入力のしやすさ
日々業務の忙しい中、工数登録をする時わざわざ普段使わないシステムを開いて入力したくないので、普段使い馴染んでるSlackから工数登録をできるようにしたい。また、人によっては喋り方も違うので、どのように喋っても、ちゃんと案件に紐づいた形で正しい稼働時間が登録されることも必要。 - この先の未来を見据えても自慢ができる社内システムであること
稼働管理ツールではプロジェクトを選んでから稼働時間を登録するのは主流の仕様ですが、社長の「この先のバックオフィス業務はすべて自然言語で行われるべき」(極論:ずっと聞き流しているAIエージェントがDesktopにいて、口頭で「今◯◯案件に1時間使った」といったらすぐに登録してくれる、そんな未来まで実現したい)思想の影響を受けて、プルダウンで選択するUIではなく、今のAIエージェントサービス風に日本語で登録できるようにしたい - 拡張性があり、様々な業務ニーズに対応できること
例えば、セキュリティ面で全員がみれるSlackのOPENチャネルで報告すると顧客情報が漏洩する可能性があるため、任意のSlackチャネルから登録ができるようにする。また、将来は業務委託や外部のパートナーの方々も使えるようにしたいため、htmlの画面から登録することもできるようにするなどなど。
更にSlackとの通信ではHTTPを使うところにもエンジニア的にセキュリティ面で不安とのことで、今回は更に別で専用のサーバーを立ち上げることによってそこそこ品質のよいシステムに仕上げました。
ここの専用サーバーの話はまたそのうち別のぶログでご紹介できればと思います。
本番稼働中の稼働管理ちゃん
使い方はとっても簡単です!
Slackの任意のチャネルから「/polybot worklog」をタイプし、その後ろに稼働情報を日本語で教えるだけで登録完了です。特に最近は音声入力が進む中、秒で登録ができるので、とっても楽です。
slackのどのチャネルからも投稿できますが、今回はデモ用にtestチャネルを作ってそこで稼働している様子をお届けします。
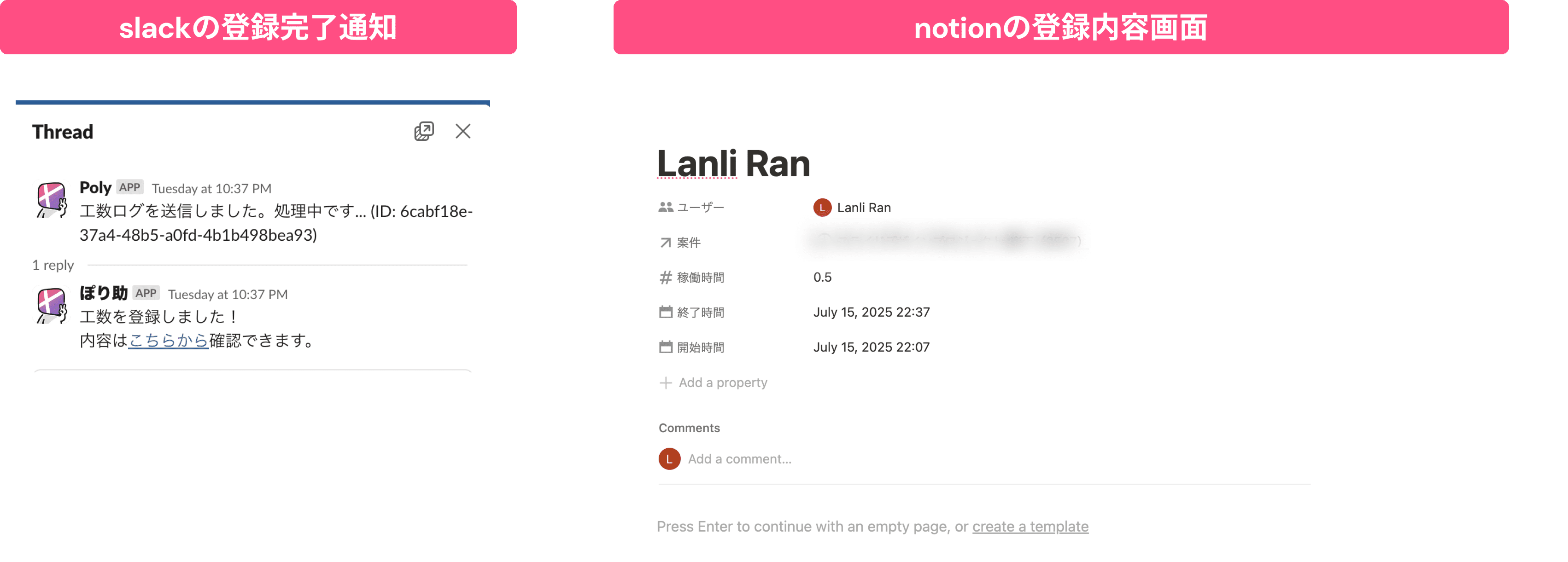
登録が終わったら、お知らせ(キャプチャをご参照)が表示されるので、Notionに登録された内容を確認したい場合は、リンクをクリックすることでNotionページが開かれて確認も楽々です♫
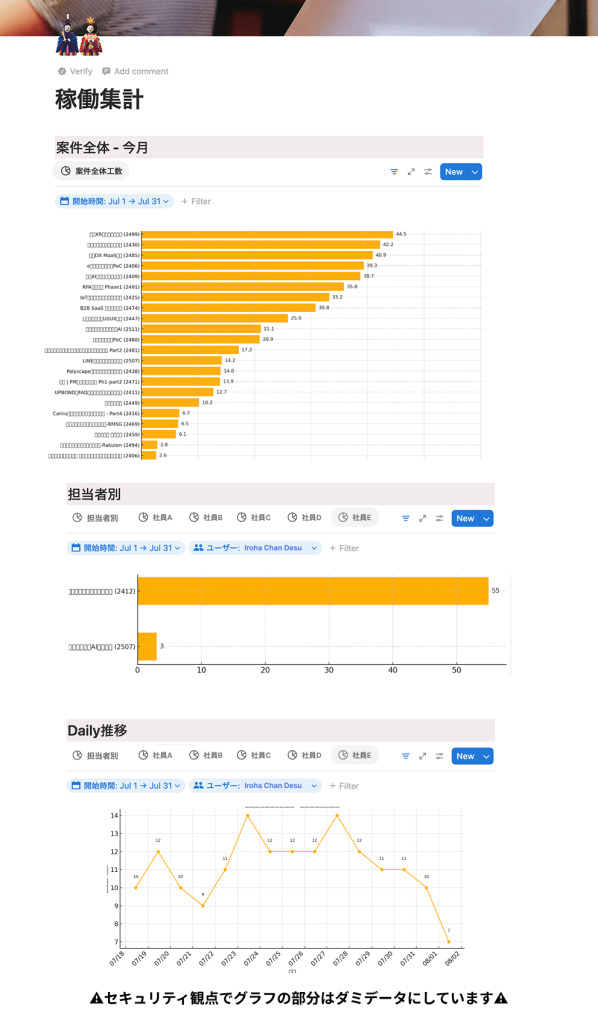
また、Notionのデフォルトの集計機能を使って案件別や、担当者別、もしくは担当者×案件など、様々な切口で可視化することができます。
作り方のご紹介
先に今回作るワークフローの全体図をご紹介します。
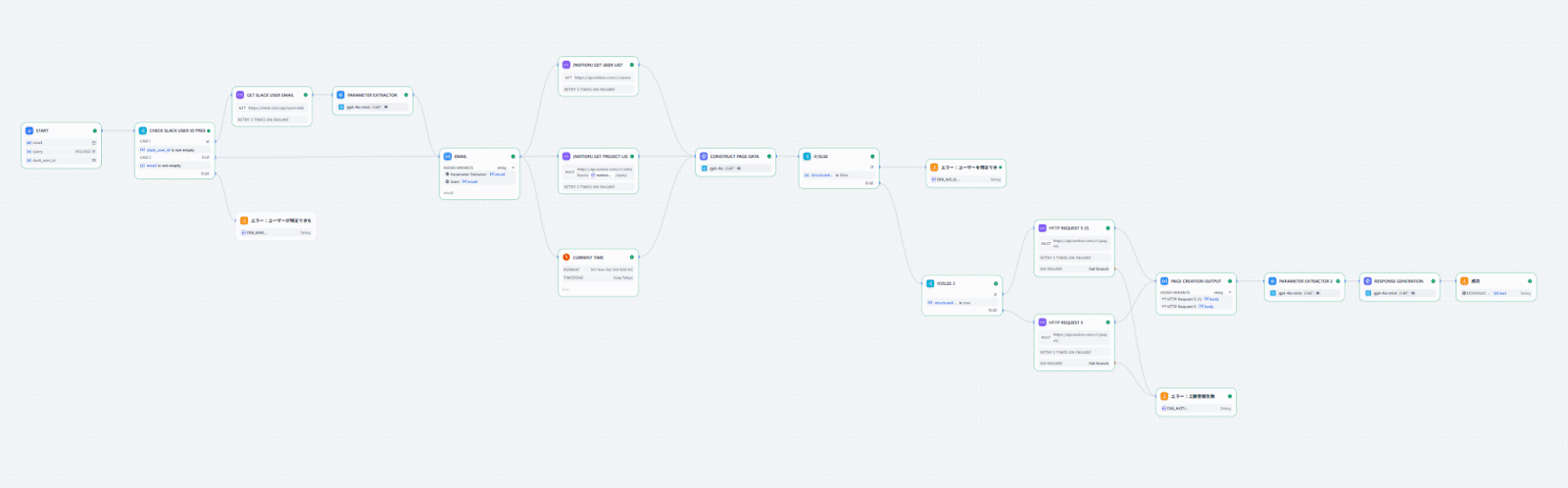
少し長く見えますが、やっていることは主に3つです。
- 必要なデータを準備する
- Notionからユーザリストを取得する
- 案件が入っているNotionのDBから案件名のリストを取得する
- ユーザーのメールアドレス取得(直接入力かSlack IDを使ってSlack APIから入手するか)
- 現在時刻
- LLMに準備した情報を渡してNotionに入れる情報を整理してもらう
- Notion APIでページを作成し、成功か失敗かをレスポンスとして返す
それでは追加するノードをそれぞれ見ていきましょう!
Step1:Startの設定
本体部分であるDifyロジックを作っていきます。Difyで新しいWorkflowを作成し、Startノードに、email, query(プロンプト), slack_user_id のパラメータを設定します。各FIELDはキャプチャからご参照ください。
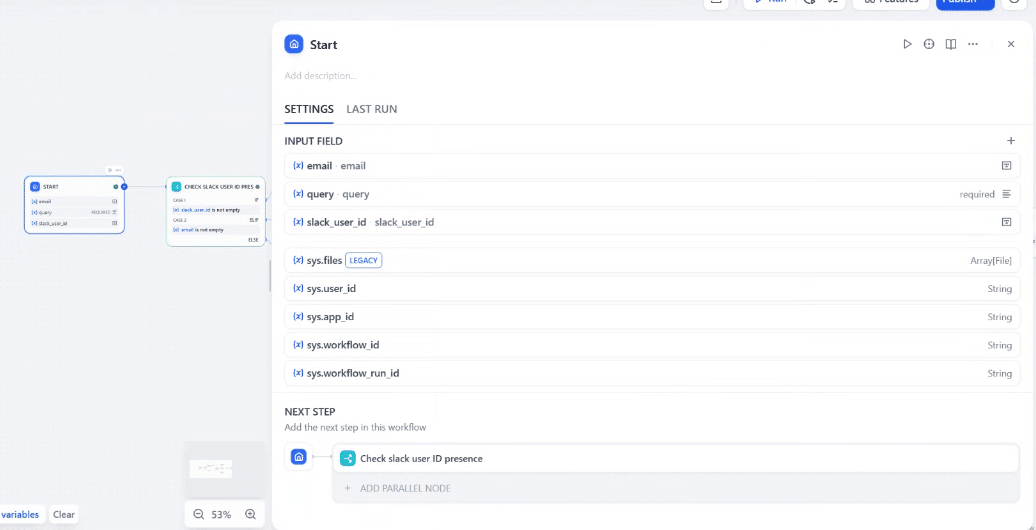
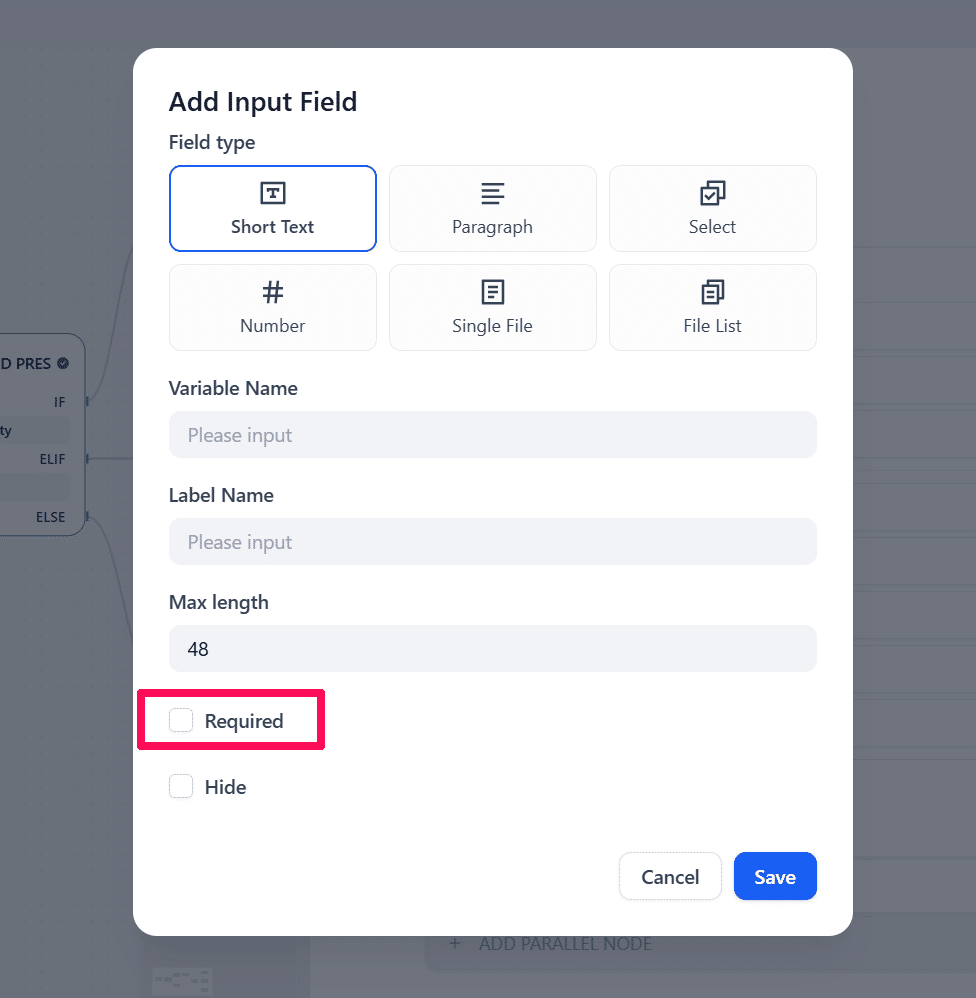
アプリ画面からでもSlackからでも投稿できるようにするために、emailとslack_user_idを両方Startに登録しますが、どちらかしか来ない想定なので、登録するときに「Required」フラグを外します。queryは社員が報告時に書く文章で必須のパラメータとします。
Step2:メールアドレスの取得
WebアプリとSlackからの投稿で、メールアドレスの取得を以下の場合に分けて考えます。
- slack_user_idがある場合優先的にSlackのユーザー情報からメールアドレスを取得する
- でなければメールアドレスが入力に入っているかを確認する(Webアプリからの投稿)
- どちらもない場合は社員が特定できないためエラーを返す
この場合使うノードは「IF/ELSE」ノードで、設定は以下の通りです:
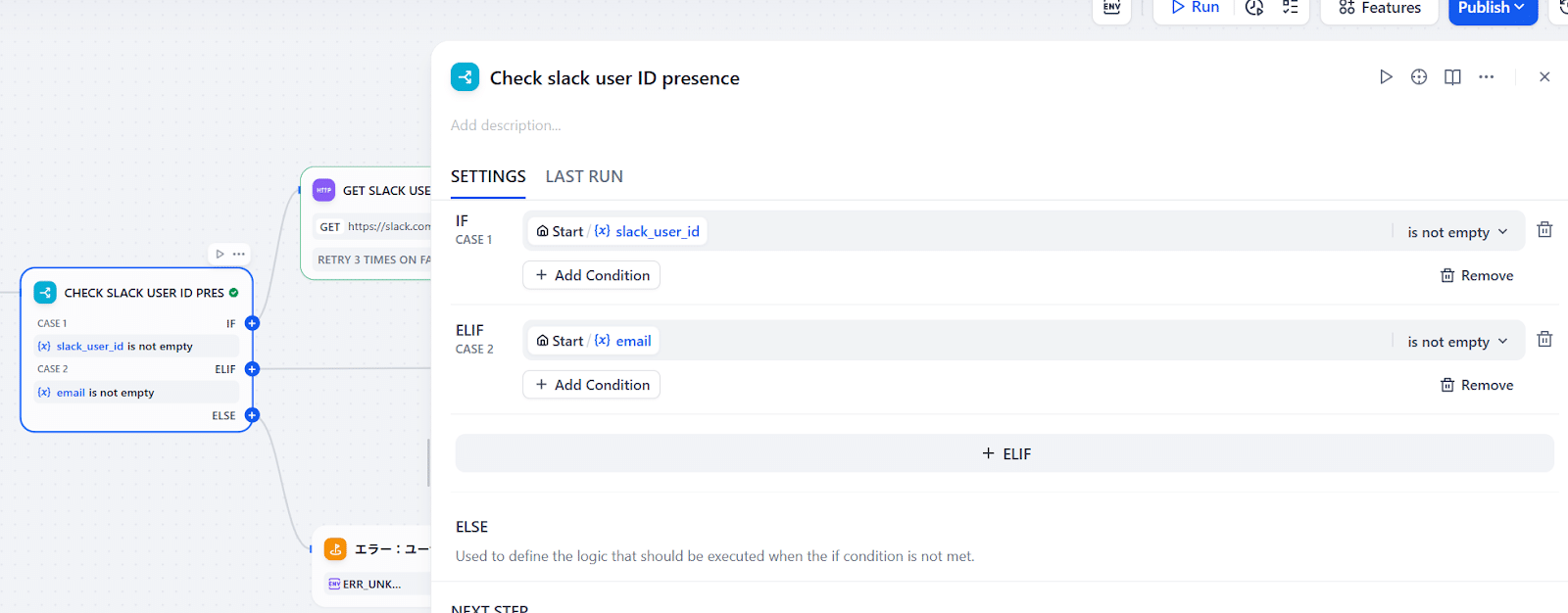
このように設定すれば、新しいノードを繋げられる場所が3つ増えます。それぞれ次に繋いでいきましょう。
slack_user_idがある場合
SlackのユーザーIDを持っている場合、今度はSlack APIを使ってユーザーのメールアドレスを取得します。Difyの「HTTP Request」ノードを使います。APIキーの設定は「HEADERS」からもできますが、ノード設定の右上に認証の簡易設定があるので今回はこちらを使います。
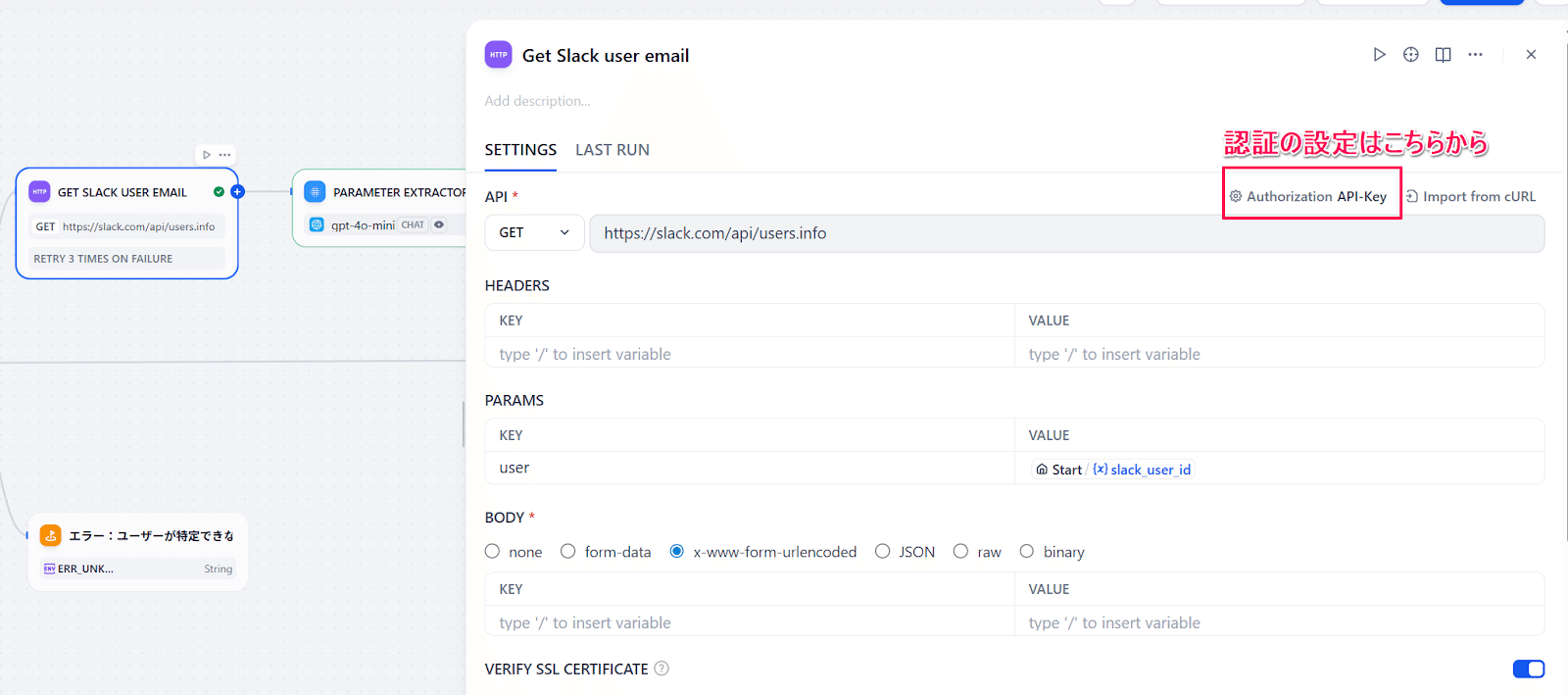
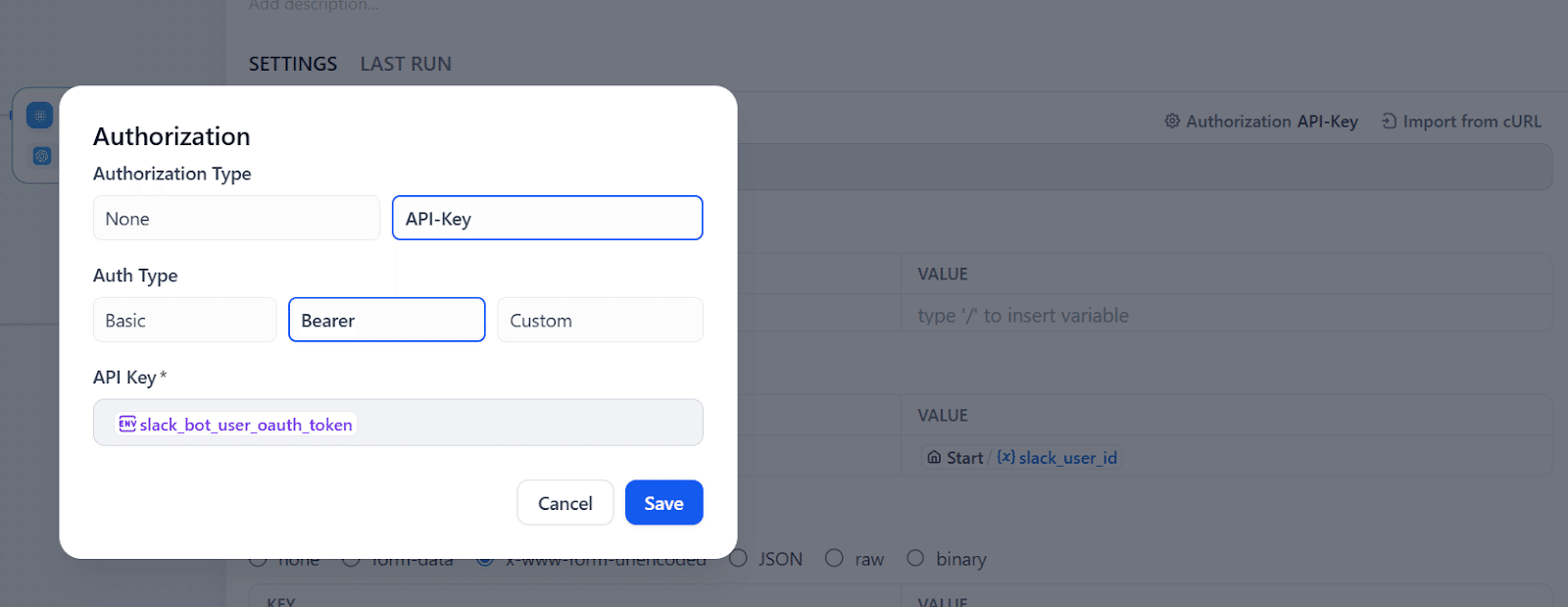
こちらが正しく設定できると、メールアドレスを含んだユーザー情報がJSONで取得できるので、今度は「Parameter Extractor」ノードを使ってメールアドレスを抽出します。ここで「何を探すか」を明確に指示できれば、それ以降のノードでパラメータを参照することができます。
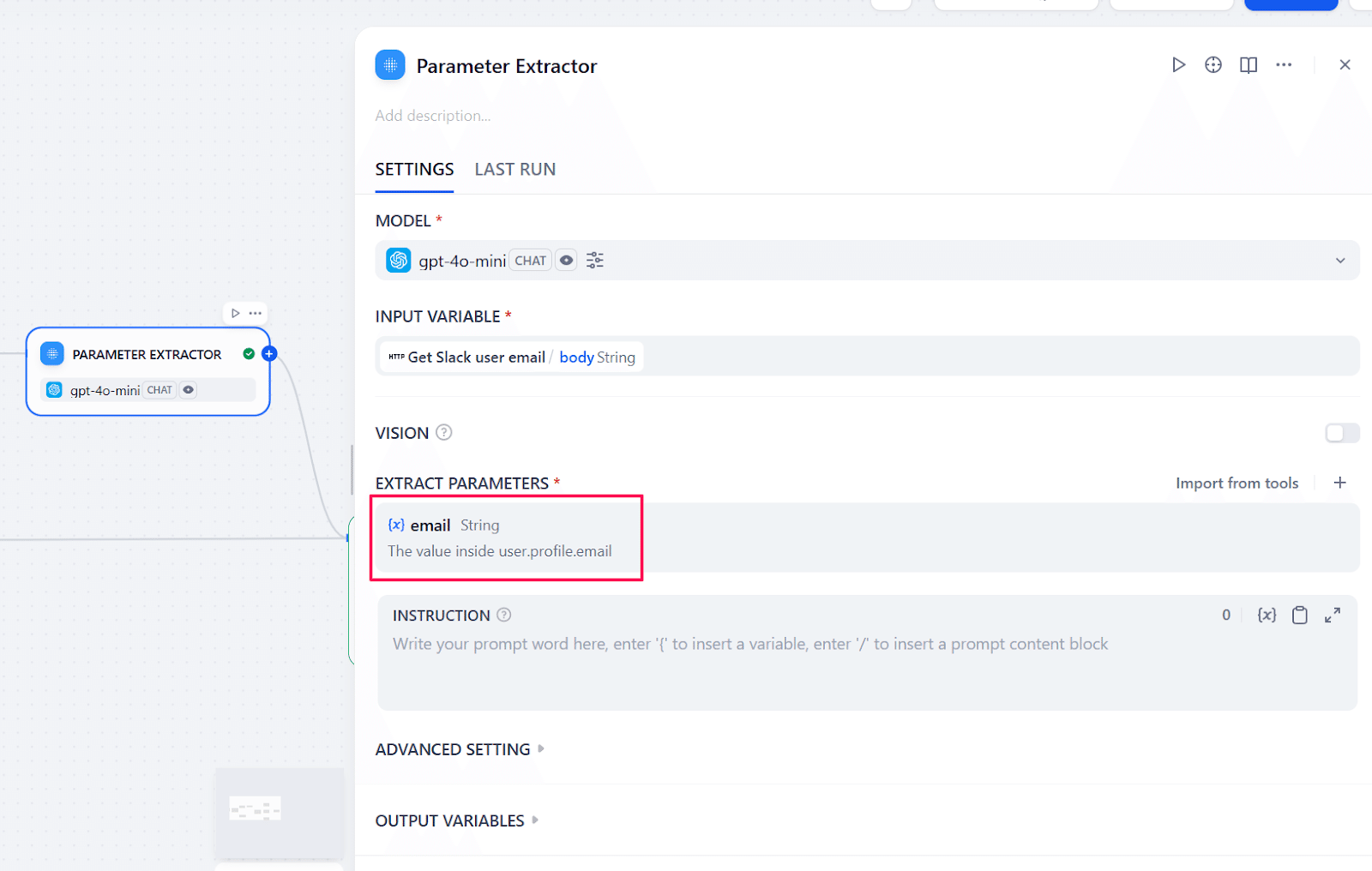
これまでのノードを以下になるようにつなぎます。
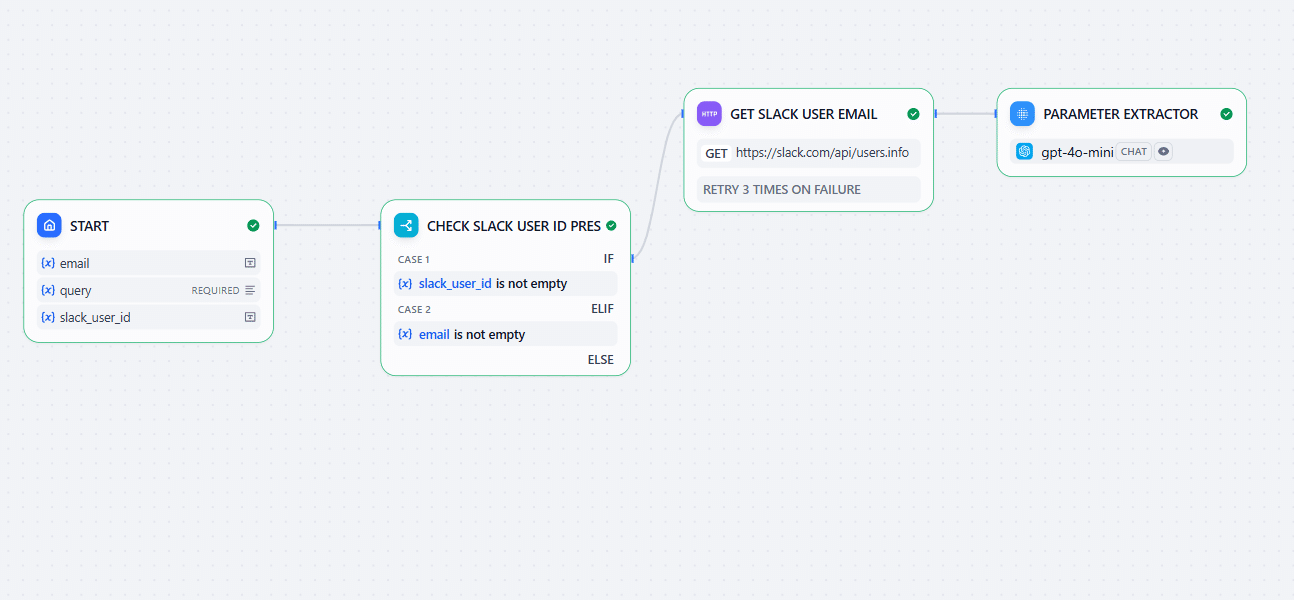
SlackルートとWebアプリルートの結合
Slackのユーザー情報からメールアドレスが取得できた場合とWebアプリから直接入力された場合と、情報の入口によって使われるものが異なってきます。それ以降のすべてのノードにおいてその条件分岐をいれる必要があれば、完成までなかなか時間がかかってしまいますが、Difyにはこの条件を見据えた「Variable Aggregator」ノードがあります。このノードは、別々のルートの出力を同じ変数にまとめてくれるノードで、画像のようにつなげば、右以降のノードでは (Parameter Extractor).emailを参照すればいいです。
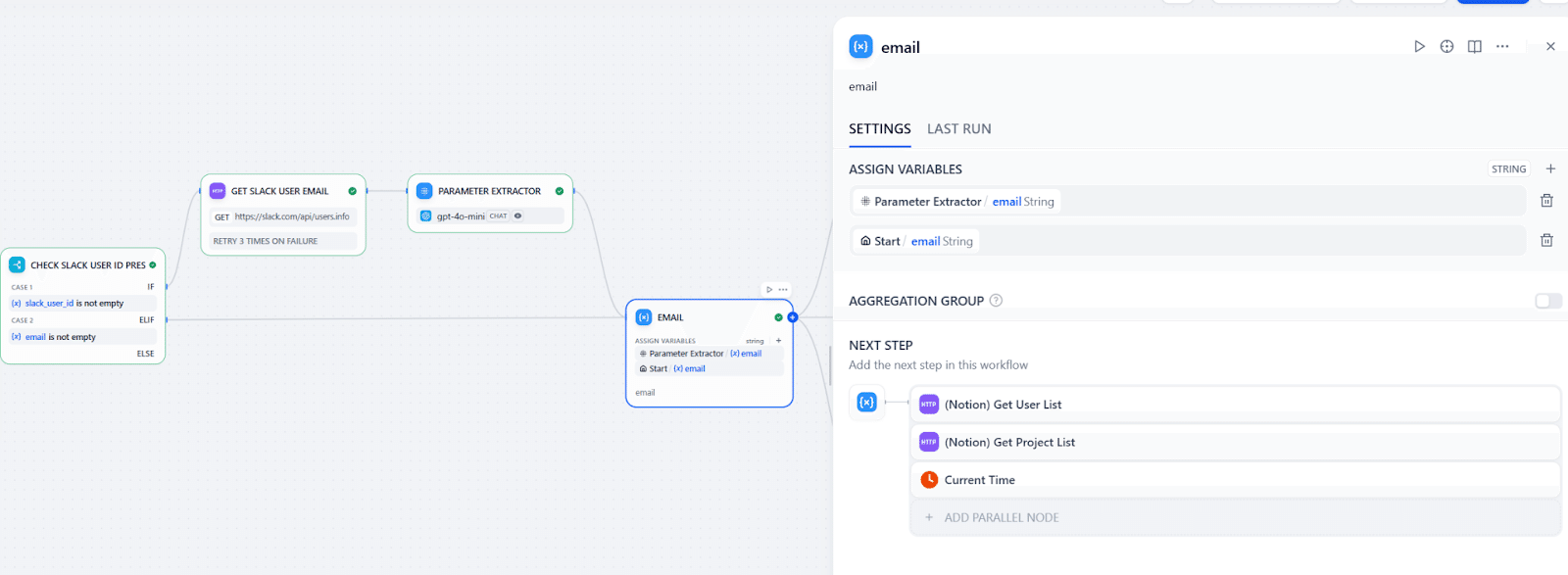
なお、残るは「IF/ELSE」ノードのELSEの部分ですが、こちらについては後ほど触れるので今度はLLMに渡す情報を準備していきましょう。
Step3:稼働情報を整理するLLMに渡すデータを準備する
ユーザーが書いた情報以外にも、「現在時刻」や、ユーザー検索のための「Notionユーザー一覧」、「NotionDBにあるプロジェクト一覧」などもLLMに渡したいのでその3つのノードを用意します。Notionに関する情報はまた「HTTP Request」で取れます。画像にあるように、一つのNotion API呼び出しにおいて1つのDBの情報しか取れないので、複数のDBでの検索を実現したい方はその分ノードを増やす必要があります。
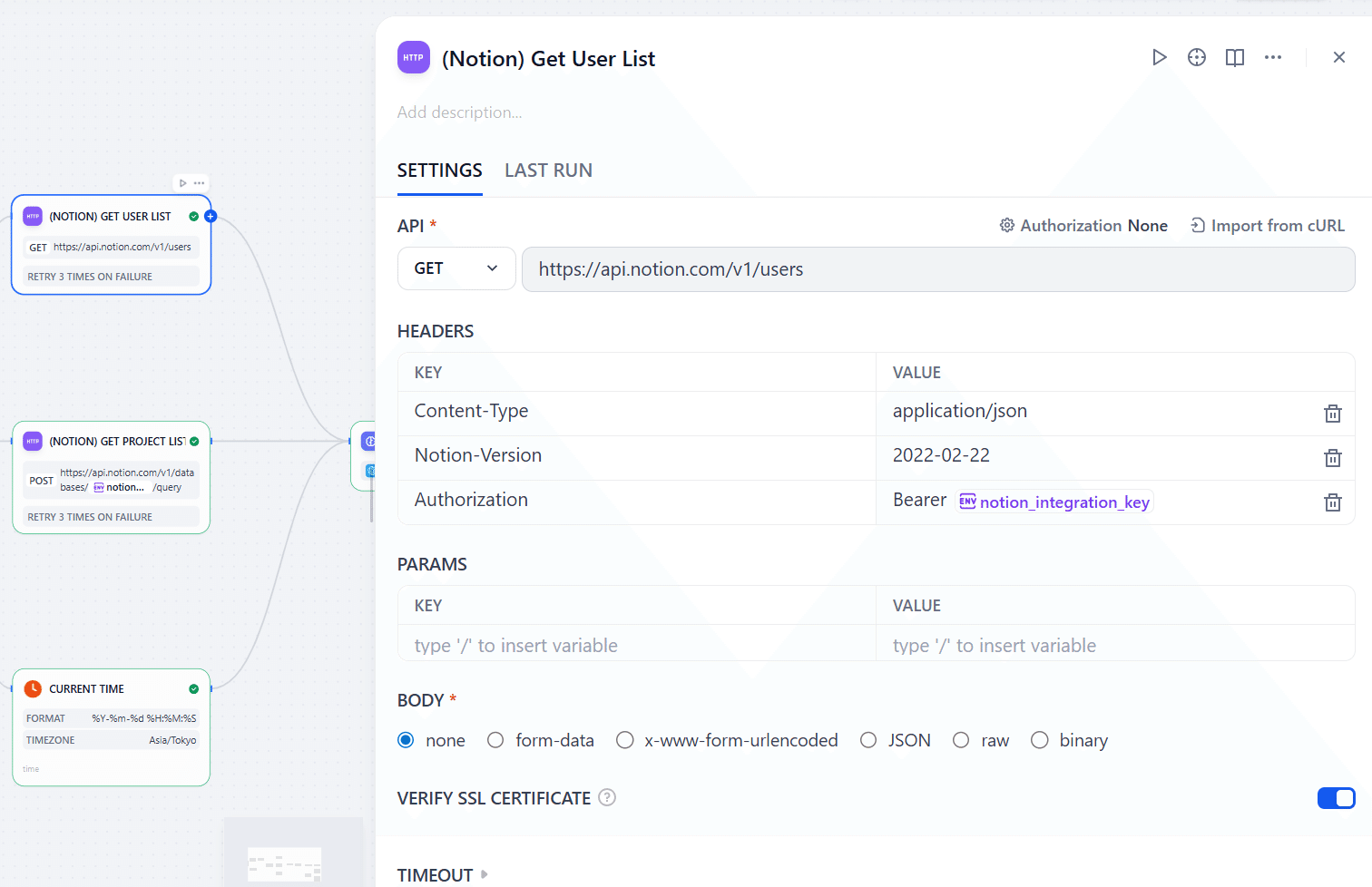
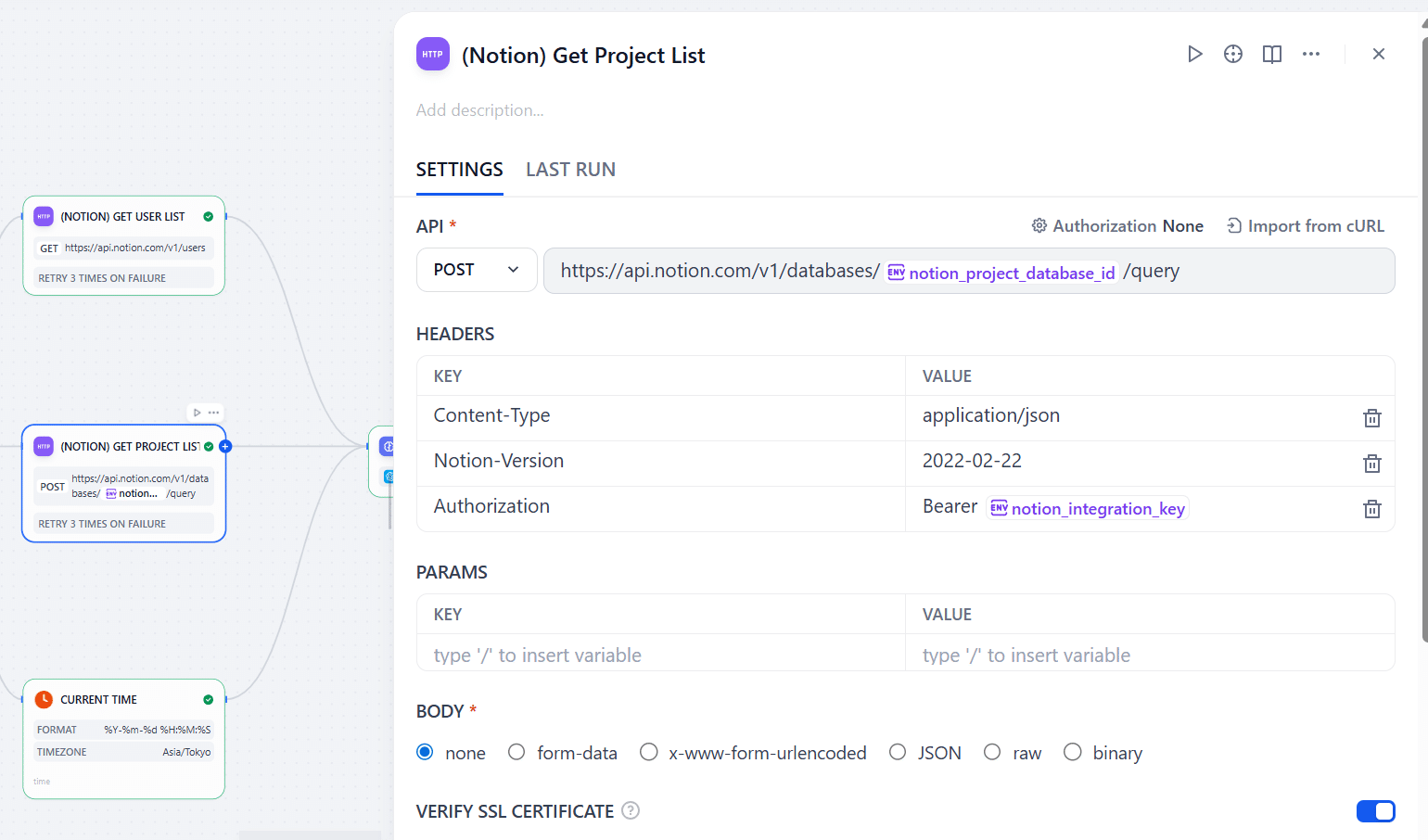
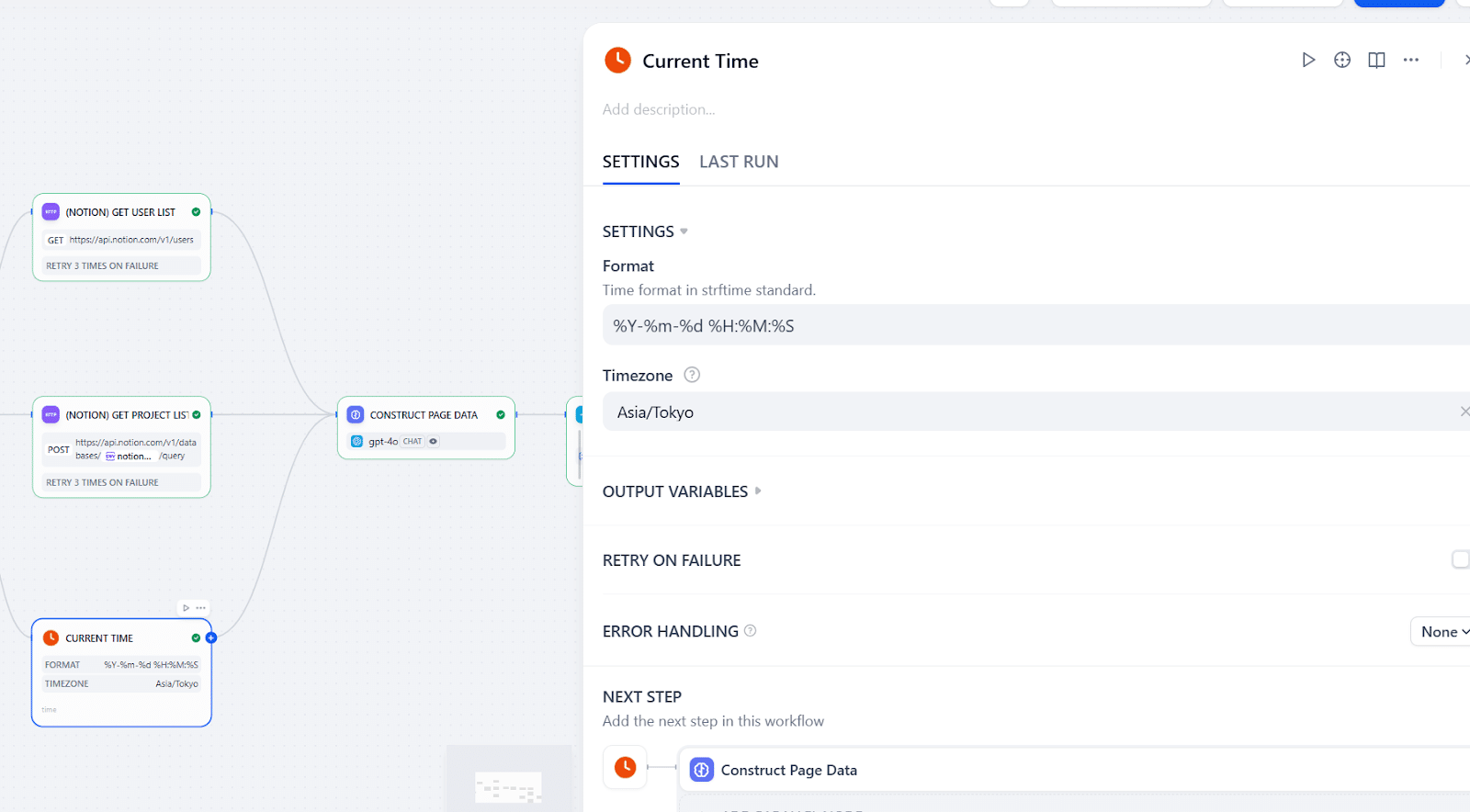
また、現在時刻はDifyの「Current Time」を使います。ここでフォーマットとタイムゾーンに気を付けるといいです。ここで決めた情報とLLMに出す指示が合っていないと想定外の動きになりやすいです。
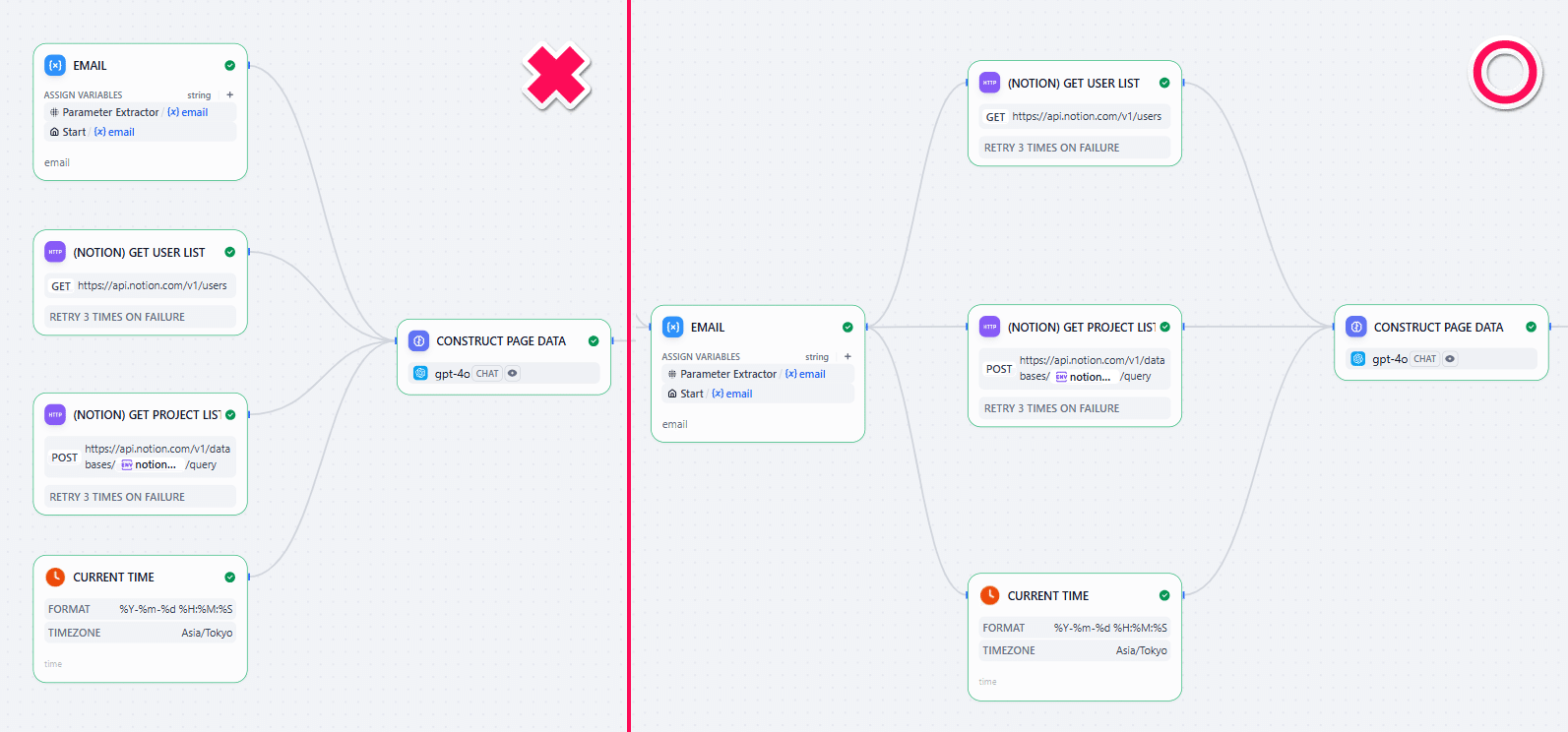
また、ノードをつなげるときに注意が必要です。これらの情報は、Step1~5のメールアドレスと関係なく取れる情報ですが、左からの入力がないノードは動きませんので、メールアドレスを持っているノードをこれらにつないでからまたLLMに繋ぎます。
Step4:稼働情報を整理するLLMを用意する
まず、「LLM」ノードを追加します。今回渡す情報が多いので、LLMを混乱させないために以下のようにメッセージを分けます。
- SYSTEMにはLLMの「人格」、「やるべきこと」
- ASSISTANTは外部から取ってきた情報とその説明文
- USERには取得したメールアドレス、報告文(query)
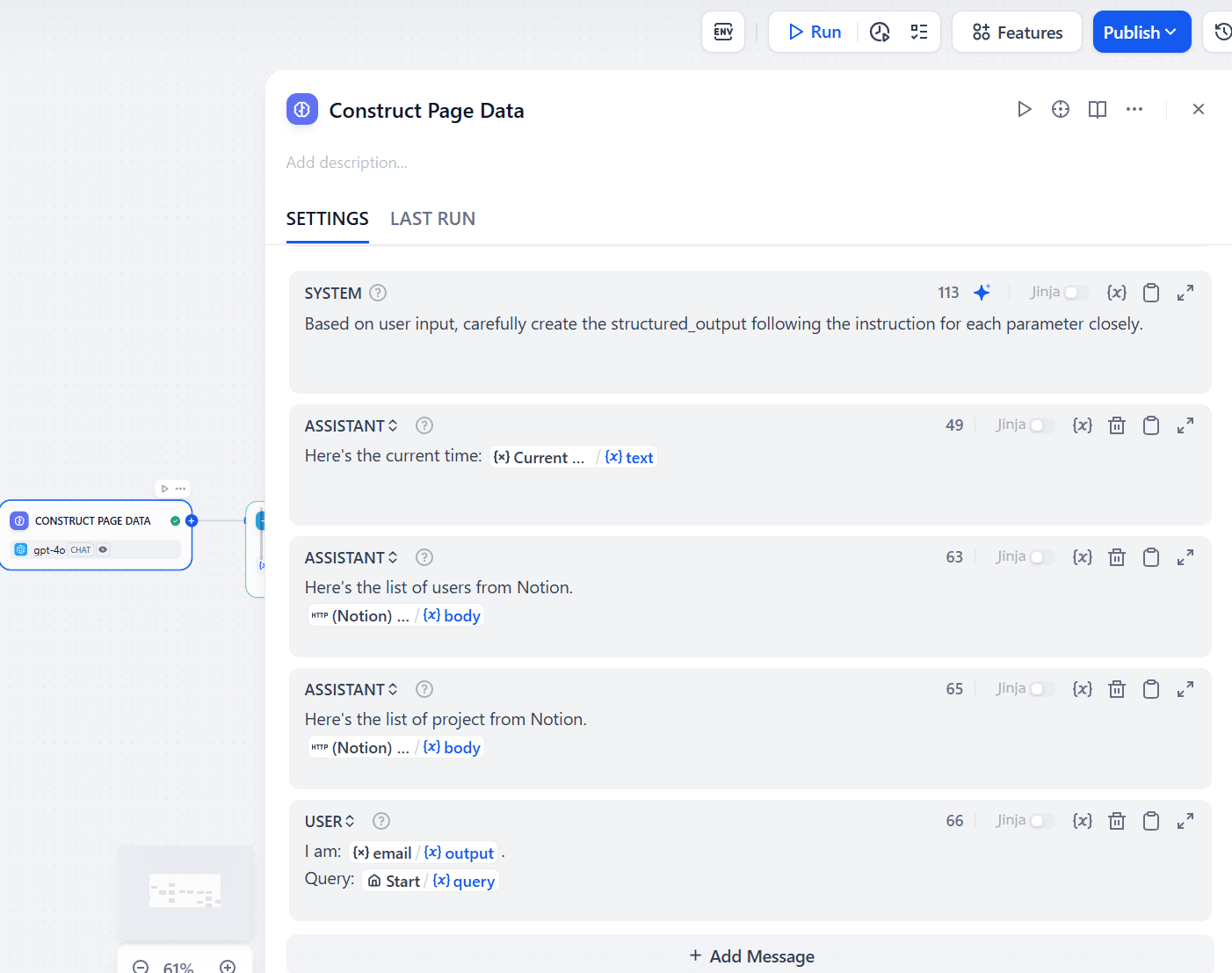
なお、SYSTEMメッセージにおいて、「メールアドレスと報告文を使って以下のようにJSONデータを出力してください」とより細かく指示することもできますが、今回は一部のGPTモデルで利用可能な「Structured Output」を使用します。(モデル:gpt-4o)
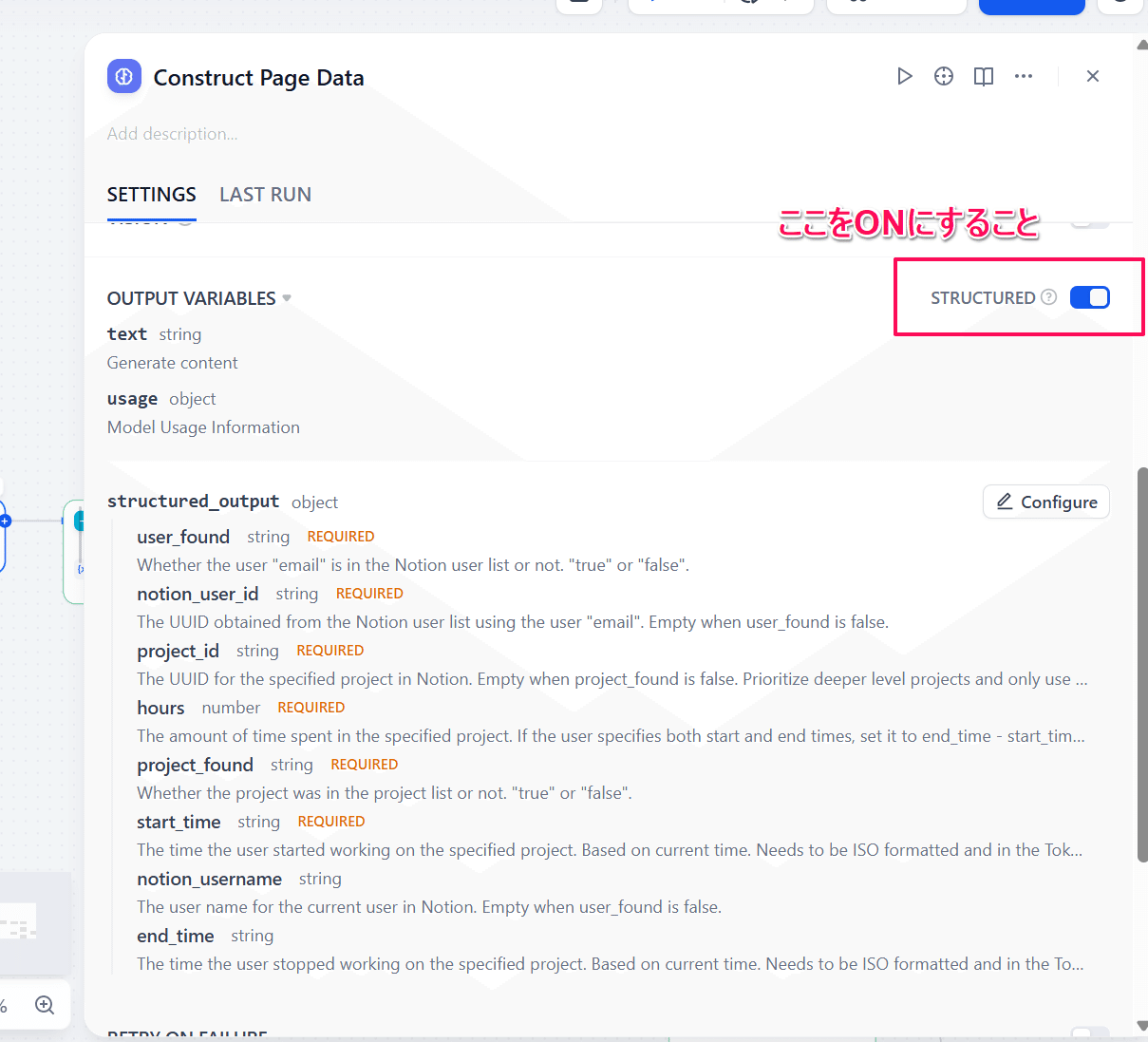
Structured Outputでは、それぞれのパラメータの型とこれらに対する説明文を設定することができます。Notionのページ作成APIにおいて必要な情報は以下の通りです。
- NotionにおけるユーザーID : メールアドレスを使ってNotionユーザー一覧から検索
- Notionにおける表示名: メールアドレスを使ってNotionユーザー一覧から検索
- 案件ID:案件名を使ってNotion案件一覧から検索
- 開始時間
- 終了時間
- 合計時間(終了 – 開始またはユーザーが指定した数字)
画像のようにこれらの値を設定する変数を用意して説明をつけます。試行錯誤を繰り返して好みによって他にパラメータを増やして、「IF/ELSE」で結果によってルートを変えてもいいです。
今回、ユーザーIDと案件ID以外にもユーザー検索成功フラグ(user_found)と案件検索成功フラグ(project_found)をおまけで作っています。これは、例えばユーザーIDに値が入っていたとしても、その値が本当に検索したものなのかLLMのハルシネの結果なのかが分からない場合もあるからです。それぞれのフラグを用意して「本当に検索できたときだけ true にして」とすることで、抽出している値が本物なのかのダブルチェックが可能になります。
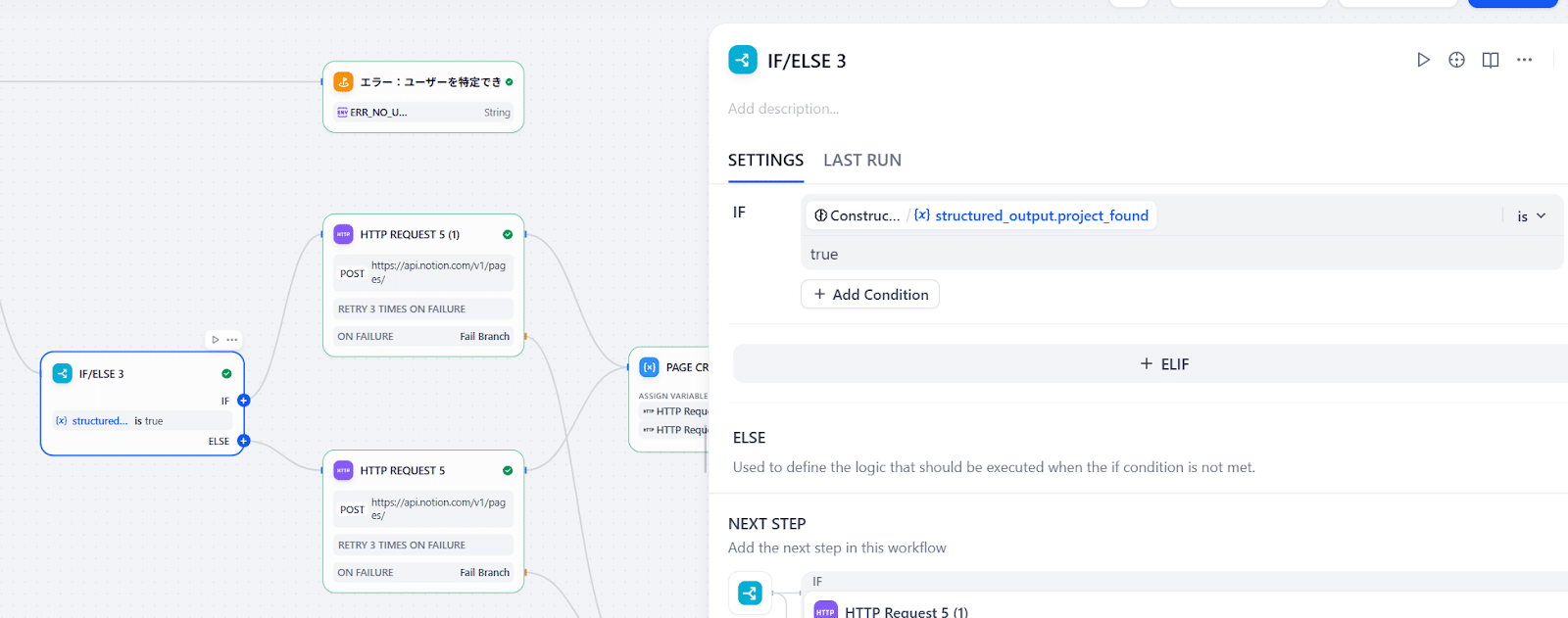
Step3のように、Notionユーザーが見つかったか否かで分岐点を作りますが、見つからなかったときの処理は一旦空にします。
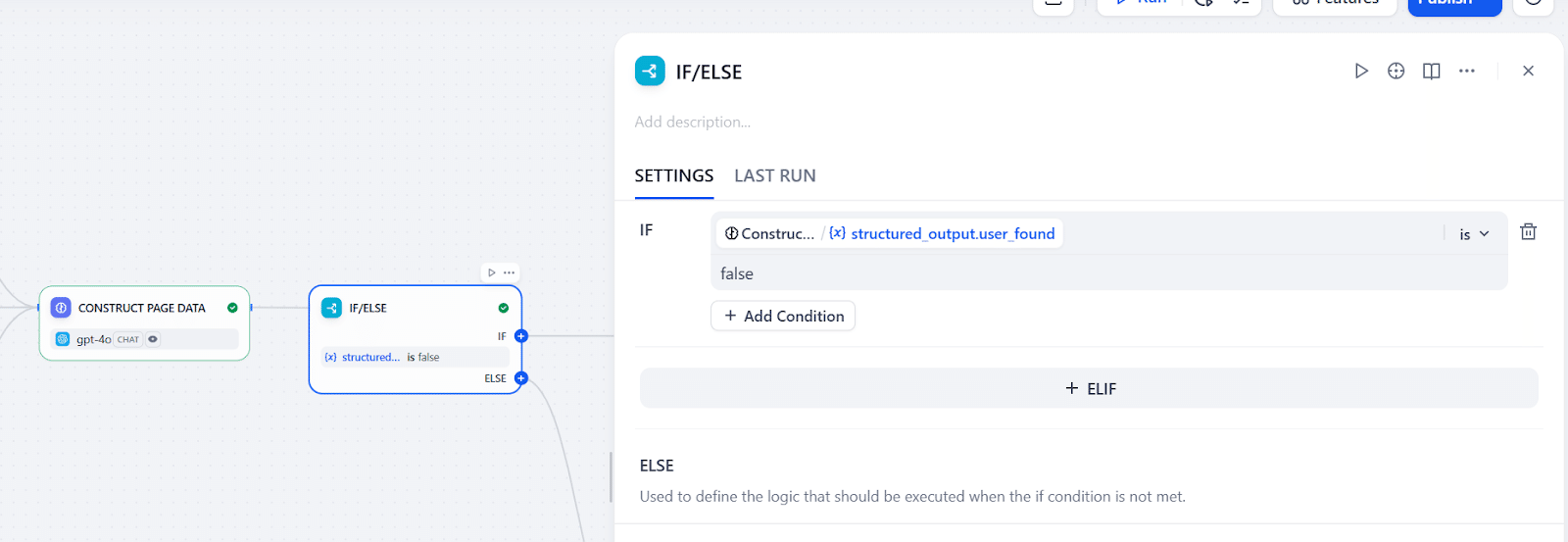
情報が整理できたら、今度はNotion APIを使って稼働情報をDBに入れます。
Step5:NotionのDBに稼働情報を入れる
今回使うAPIはNotionのページ作成APIです。
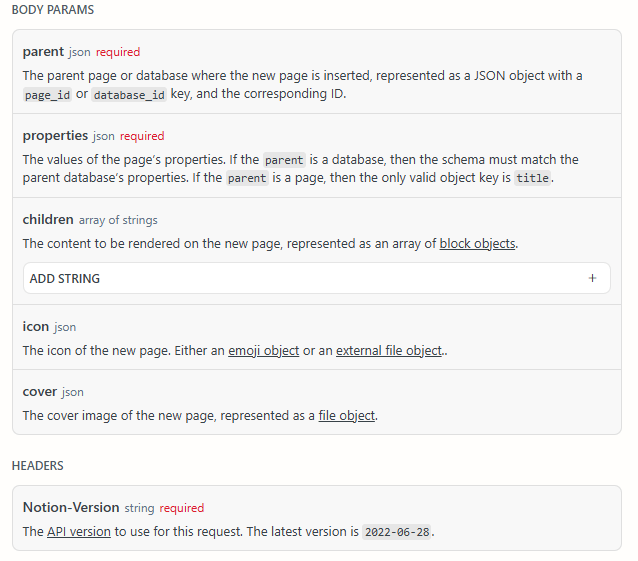
ドキュメントのように、parentには対象データベースのID(NotionのURLに書いてある文字列)、Notion-Versionには固定の文字列を設定すればいいので、あとは中身のpropertiesが正しくフォーマットできれば入力できます。しかし、書いてあるようにparentがデータベースの場合、propertiesの中身がデータベースのスキーマと一致していないと400(Bad Request)になってしまいます。カラムタイプに「テキスト」、「数値」、「日付」、「リレーション」と、様々な型が含まれており、それぞれのデータ構造が異なるのでこちらのページを参照しながら書きます。
一つだけ例をあげると、今回私たちがNotionで用意したDBの「ユーザー」は単なる文字列ではなく、Notionのユーザー一覧から選べる「~~さん」という属性になっています。これに合わせてデータをAPI経由で登録してもらう場合、LLMが検索したNotionユーザーIDを使ってリクエストのJSONに以下のように書きます:
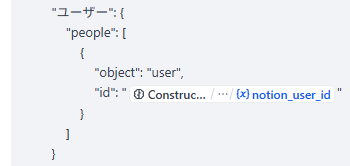
一通り設定できるノードは以下のような構造になります。
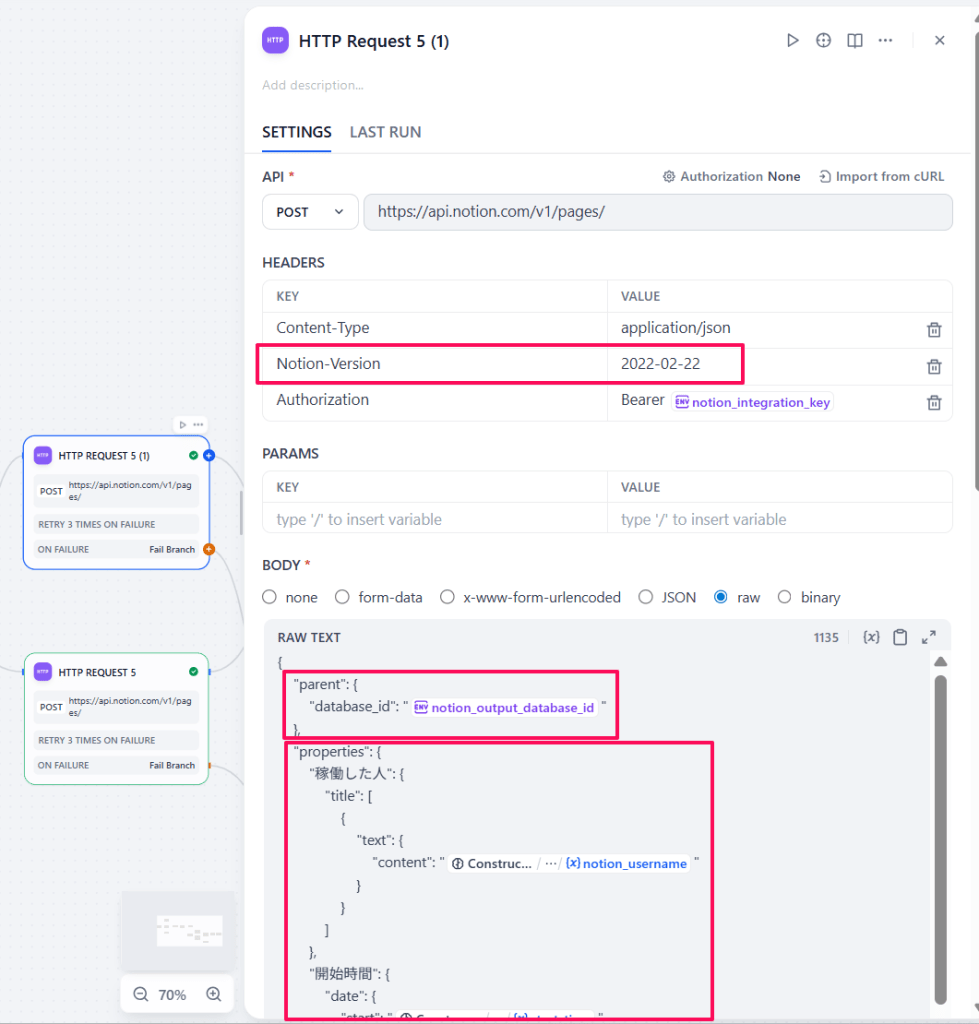
また、プロンプトによってLLMの検査精度が想定値にならないこともあり、案件名に関しては見つかったら登録したいのですが、見つからなくても空でNotionに登録したいという仕様で今回ワークフローを作っています。Notion APIでは、使わないパラメータはJSONから省く必要があるので、「IF/ELSE」で案件名を使う場合と使わない場合を分けて、APIに入れるJSONも変えています。
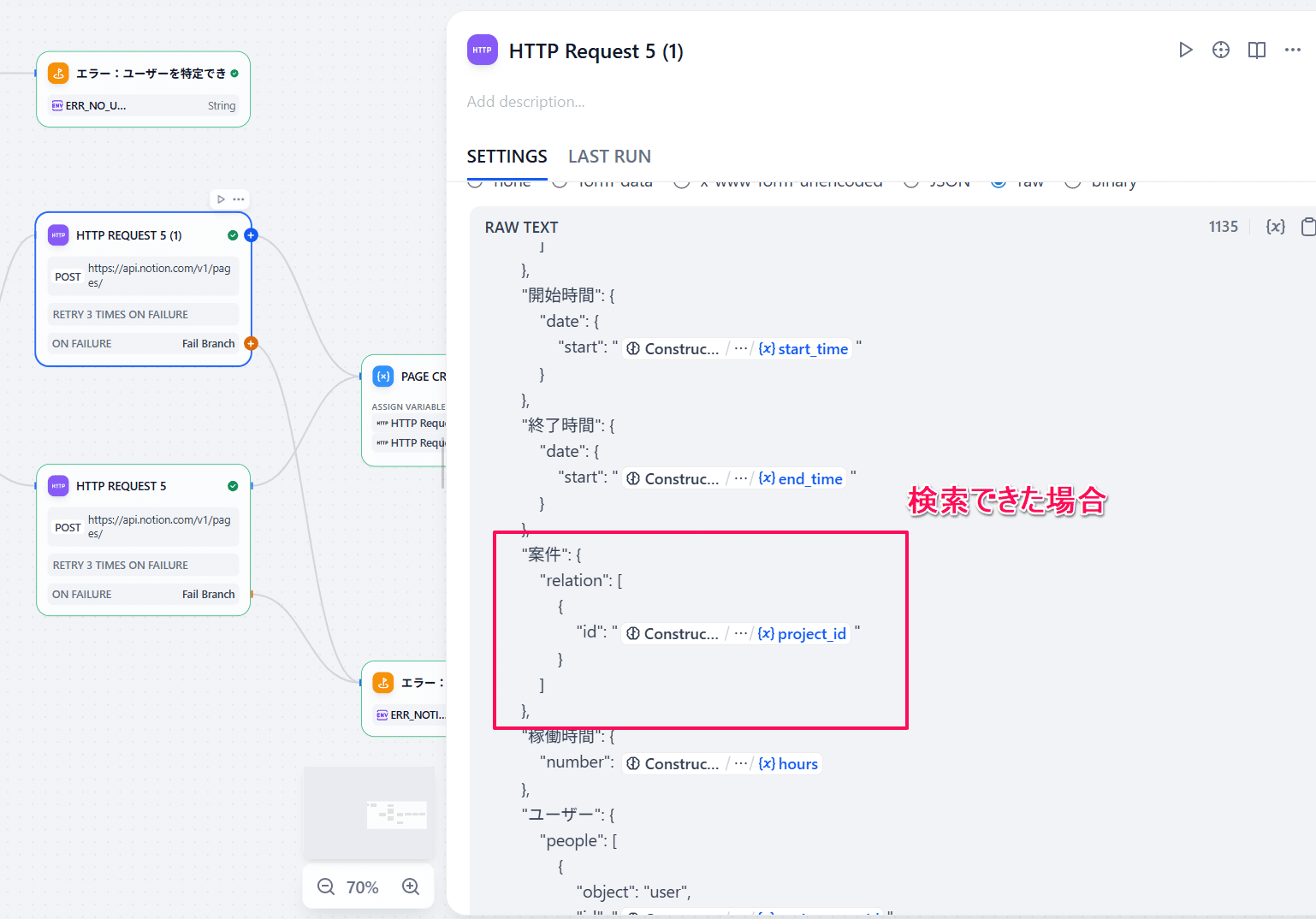
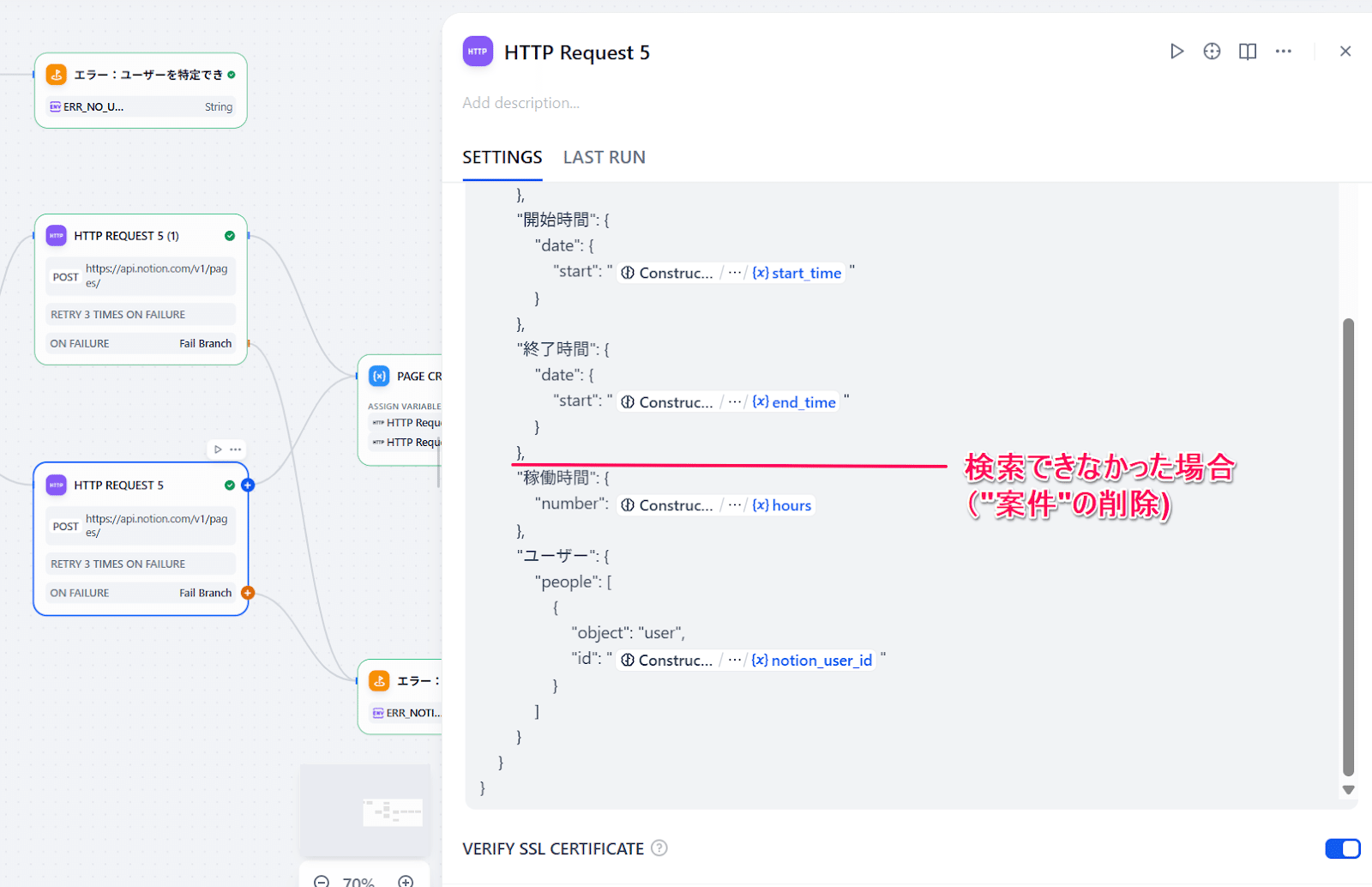
ここが一番重要な要素なので、事前にPostmanやcURLなどで動作確認をしてからDifyのノードを準備するとスムーズです!
Step6:レスポンスを返す
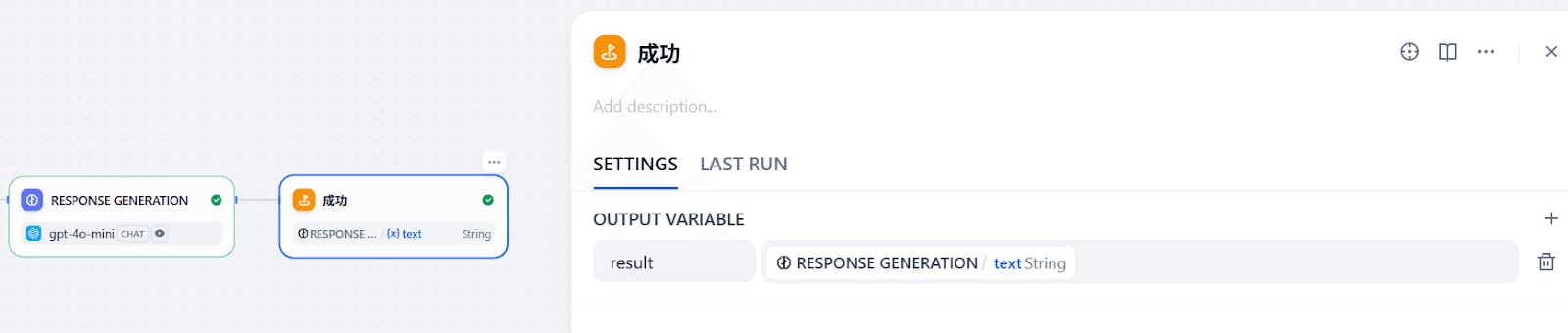
成功時の返信文をLLMに考えさせる
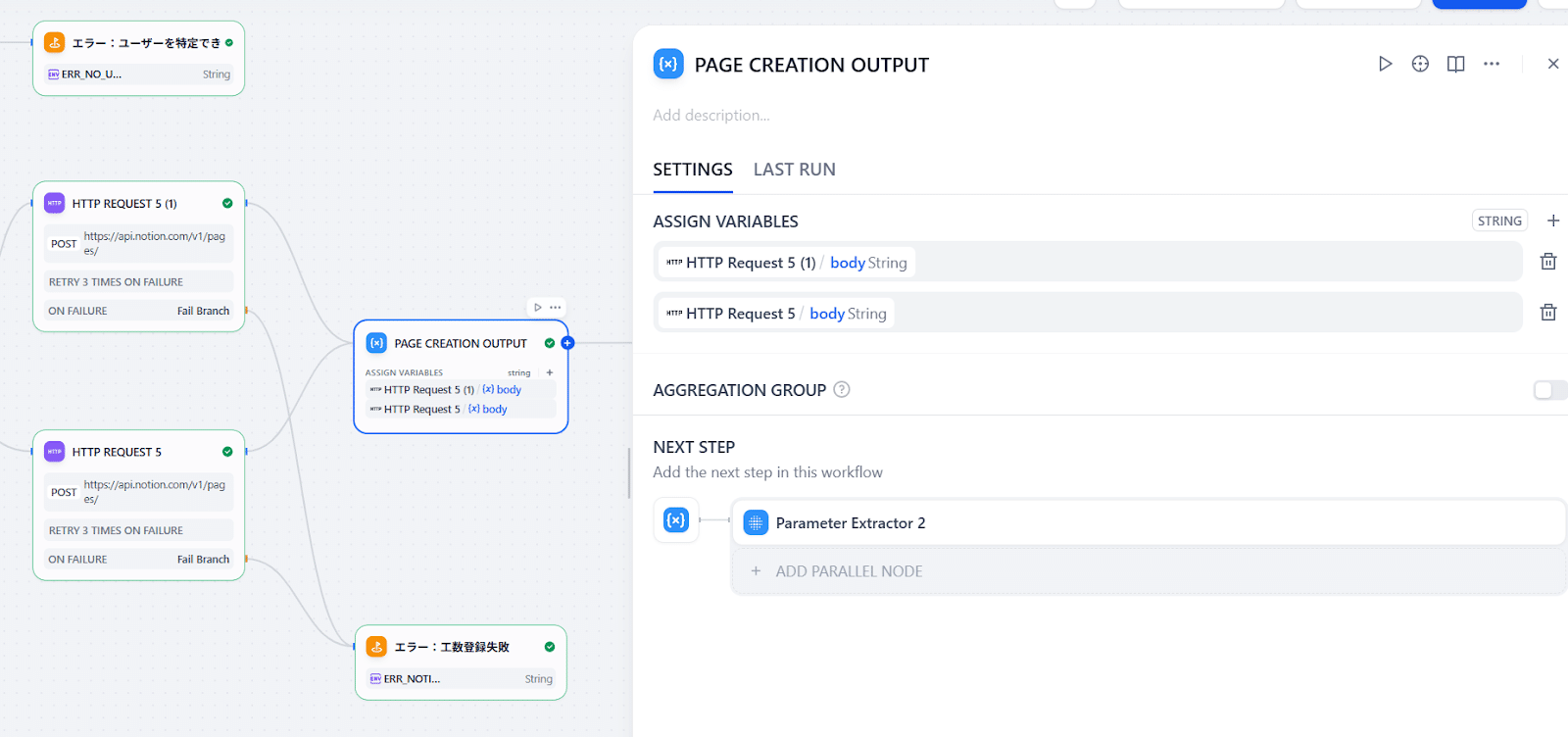
成功した場合、投稿した社員に「登録できました!こちらのページにあります。」と返したいとします。Step1~5のおさらいになりますが、最後にやることは:
- ページ作成のルートが2パターンあるので、どのルートを通ってもレスポンスが同じ変数に入るようにする(Variable Aggregator)
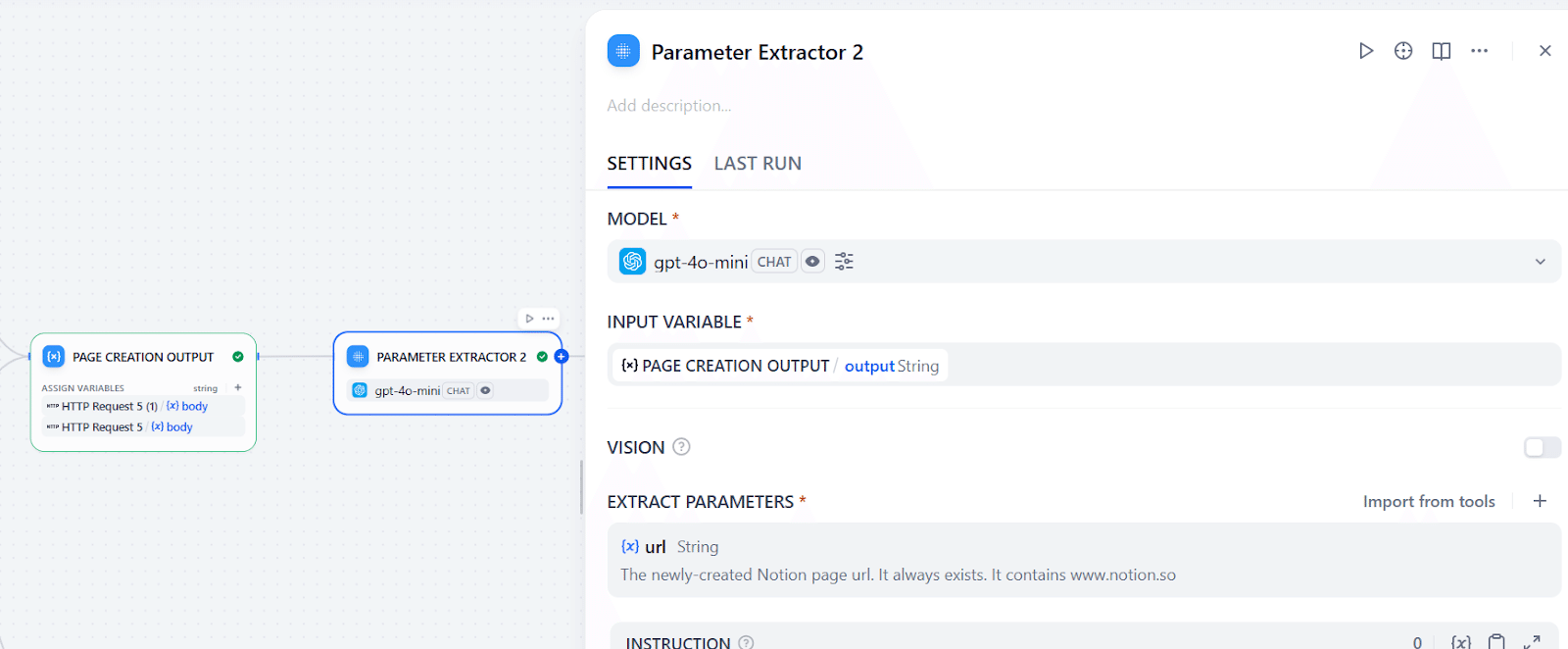
- そのNotionのレスポンスから、作成したページのURLを抽出する(Parameter Extractor)
- URLを渡してLLMに返信を考えてもらう(LLM)
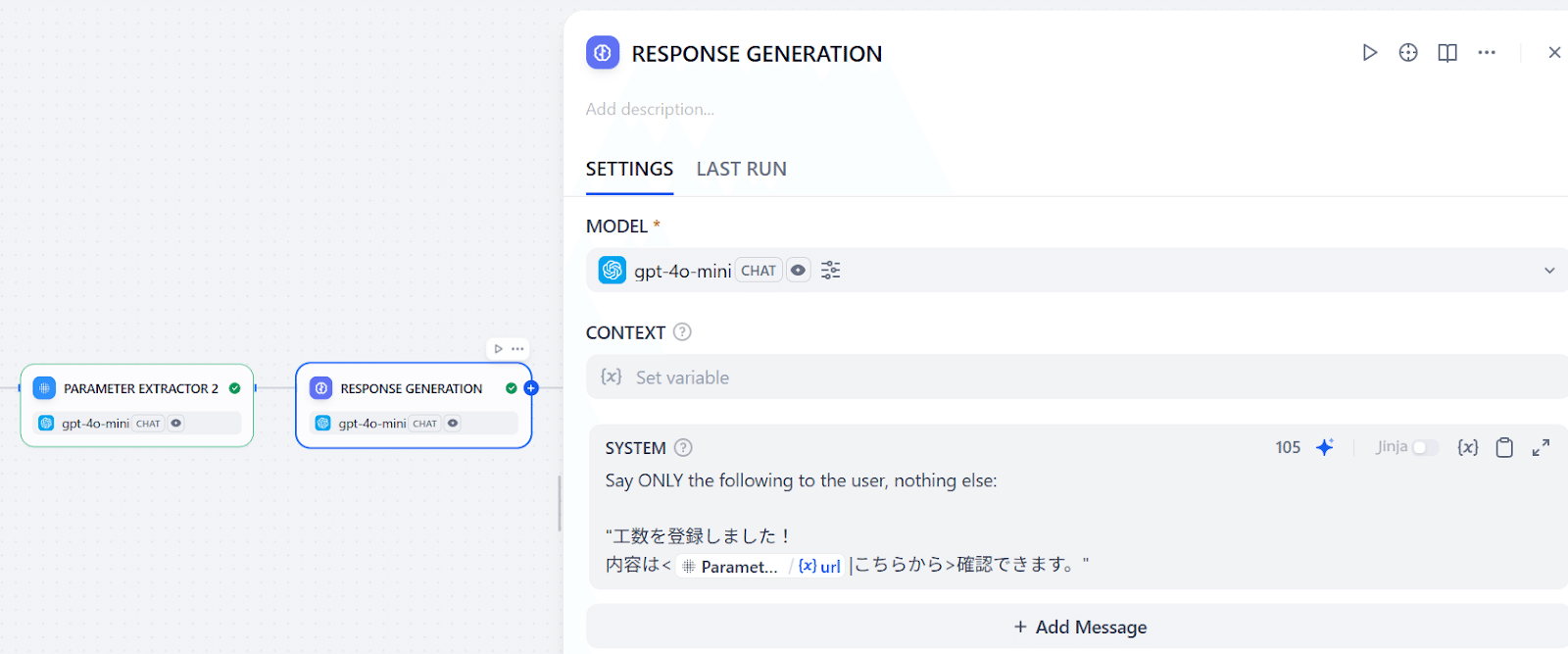
これで、作成したページURL込みでレスポンスが返せます!さて、ワークフローを使っているクライアントにどうやってレスポンスを返すか見ていきましょう。
「End」ノードでレスポンスを返す
これまで作ったワークフローの中には、「メールアドレスがなかったら終了」や、「LLMがユーザーを特定できなかったら終了」などと、失敗ルートを含めて終了ポイントがいくつかあります。しかし、それぞれのルートにおいて返すべきレスポンスをDifyは(当然)勝手に生成しないので、開発者で定義してあげる必要があります。「End」ノードを以下4カ所に追加します。
- slack_user_id、emailどちらも提供されなかったルート
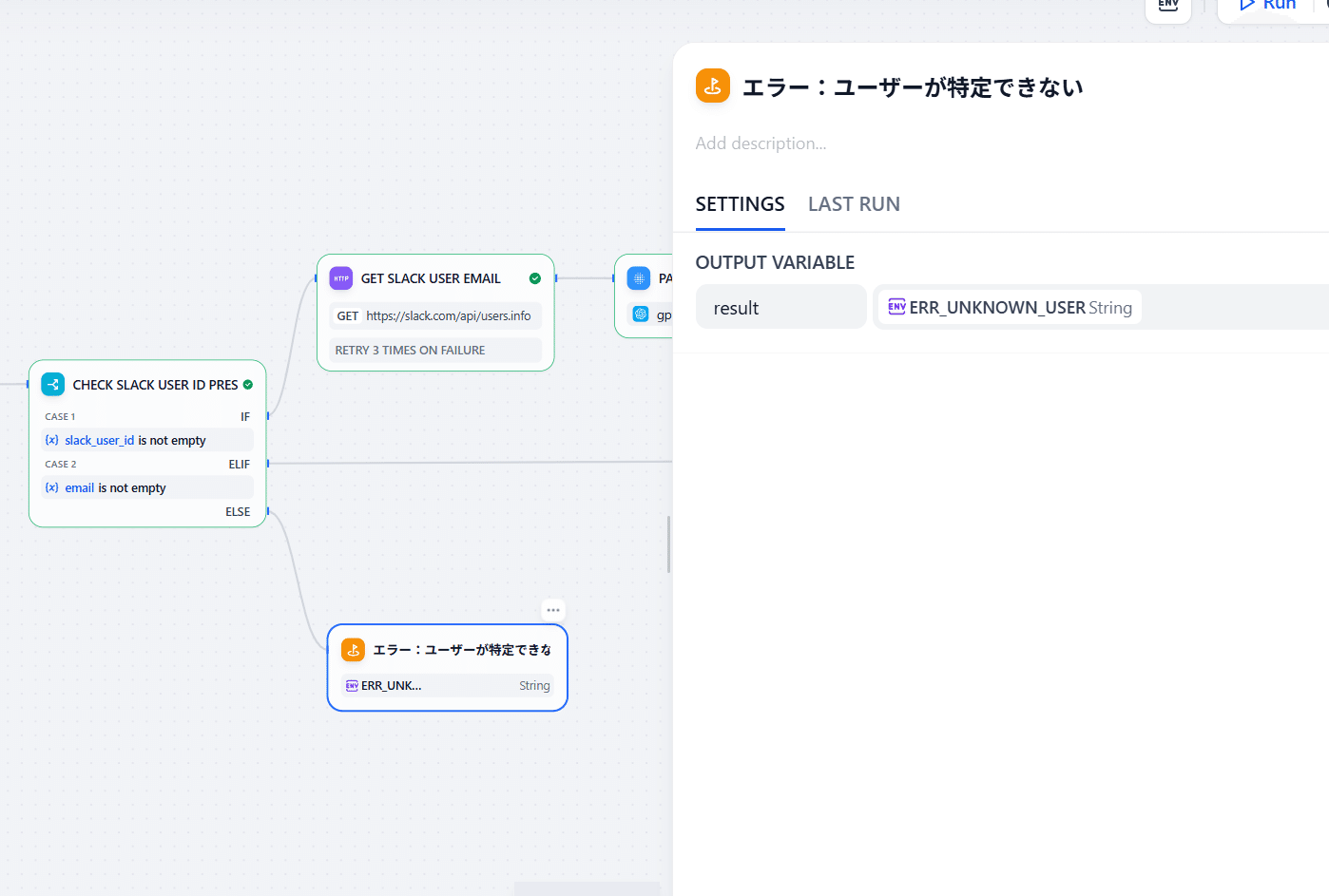
- LLMが検索してもuser_foundがfalseになったルート
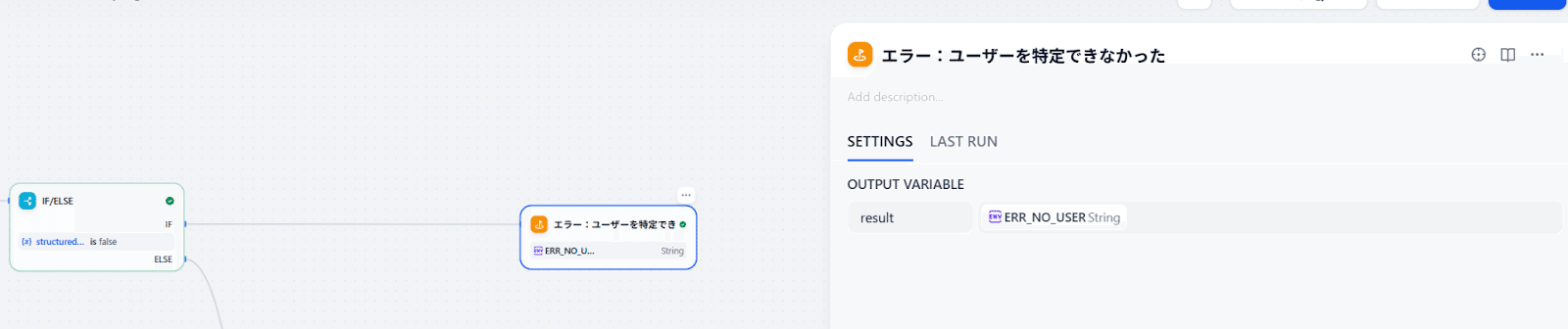
- Notion API実行時にエラーが起きたルート
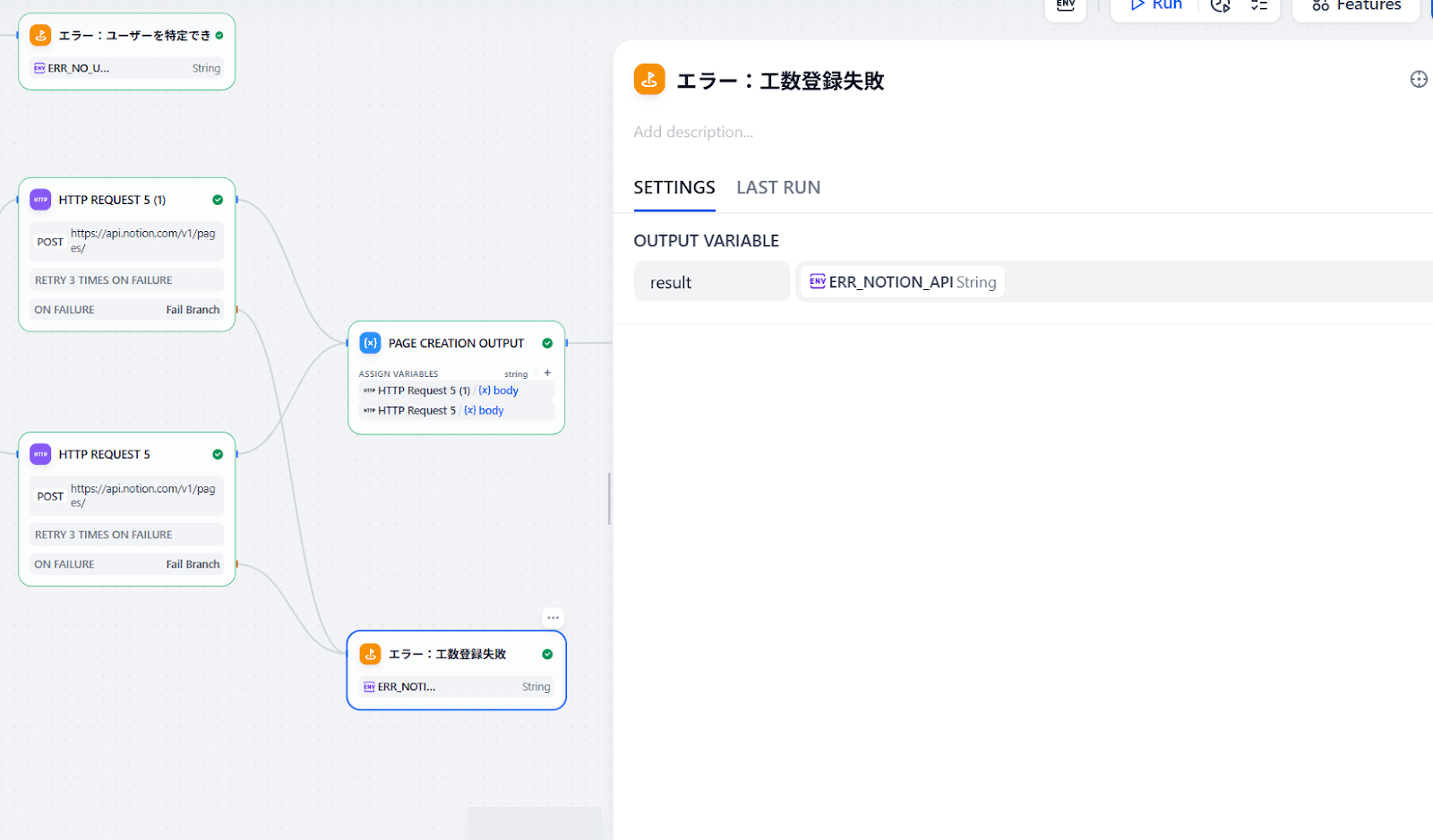
- 成功ルート(URLを含めた返信文を返す)
ここまで設定できて最初の全体図と同じ繋ぎ方ができればワークフローの完成です!
が、SlackからはどうやってDifyを呼び出して、返したレスポンスがどうSlackに投稿できるのか気になるところですね。
Slackアプリ ↔ Difyのやりとりについて
今回は深いところまでご紹介できませんが、一言でいうとSlackアプリがDifyとやりとりするためのバックエンドも必要です。
SlackのGUIだけを使ってアプリを作るとき、ワークフローやスラッシュコマンドなどで外部URLにPOSTリクエストが送れるという情報が出てきます。しかし、そのPOSTの中身が決まっており、カスタマイズすることができません。一方、私たちが今回作ったワークフローはslack_user_id、queryのようなパラメータを入力としており、リクエストに入れる方法がないと正しく呼び出すことができません。そうなると、Slackが直接Difyとやりとりできないということになります。
そこで自社で用意しているのは、Slackアプリがソケットモードで接続するオンプレのサーバーです。バックエンド側では、
- Slackの通常のPOSTリクエストを受け取る入口
- そのPOSTリクエストからSlack IDと文章を取得し、Dify用に用意したPOSTリクエストに埋め込む
- Slackに「受け付けた」旨を伝える投稿をし、その投稿のIDを保存する(スレッド作成用)
- Difyから返ってきた返信を同じスレッドに投稿
のコードを最低限実装できればSlack↔Difyのやり取りが可能になります。
.NET用のSlackライブラリがいくつか開発されており使いやすいものが多いので、C#で書くとスムーズです!
作り親にもインタビューをしました
こちらの稼働管理ちゃんを開発したのは、弊社AIエンジニアの🐜さんです。
今回の記事を書くにあたって🐜さんに軽く感想を取材した内容を参考として貼ります。同じ社内でAIエージェントツールを開発したい仲間にご参考になれたら光栄です。
Ran:今回Difyを使って開発してみた🐜さんの感想を聞かせてください。
🐜さん:Difyのおかげで短い開発期間で今回の「稼働管理ちゃん」を開発することができました。もちろん、期間が短い分、改善余地も一定残っているかと思いますが、自分としては「イテレーティブ開発を重視しており、運用していく中でバージョンアップしていきたい」ので、Difyはそういう意味では非常に使いやすいツールだと捉えています。
Ran:今回の開発はエンジニアからみては難易度はどのようなものでしょうか?
🐜さん:自分からしては作るのが簡単なんです。ここでいう簡単というのは、
- 別にDifyにあるもので完結できたので自分でマニアックなコードを書いてない
- インフラはいらない:バックエンドを用意する必要がありますが、社内はすでにSlackBotがあったのでそのあたりの開発が省かれたのでワークフローに集中ができた
の2点から見た開発のしやすさを指します。
Ran:Difyって一体どこがすごいですか?
🐜さん:まずはイテレーティブ(*1)開発がしやすいですね。
1-clickでデプロイできて、一度デプロイしたもののリンクをユーザーに共有したら、そのあとワークフローをいくら編集しても本番環境に支障が出ないので安心して開発できます。これができると、最初は「Notionにデータを入れるボット」を作ってそのあと「Slackから投稿できる」や「条件分岐でNotionに入れるデータが変わる」などを順番に付けていけます。
そして、長いデータの中からパラメータを探してくれる「Parameter Extractor」もかなり使いやすいです。
例えば、Slackから投稿して外部ツール(Notion)に同じユーザーとしてデータを登録したいとします。こういうときに全部のサービスに登録されていて、わかりやすい情報といえばメールアドレスですね。というこどでSlack APIを使ってIDからユーザー情報を取得します。そうするとこんなのが出てきます:
{
"status_code": 200,
"body": "{\"ok\":true,\"user\":{\"id\":\"XXXXXXXXXXX\",\"name\":\"user.name\",\"is_bot\":false,\"updated\":1751890667,\"is_app_user\":false,\"team_id\":\"XXXXXXXXXXX\",\"deleted\":false,\"color\":\"9f69e7\",\"is_email_confirmed\":true,\"real_name\":\"User Name\",\"tz\":\"Asia\\/Tokyo\",\"tz_label\":\"Japan Standard Time\",\"tz_offset\":32400,\"is_admin\":true,\"is_owner\":false,\"is_primary_owner\":false,\"is_restricted\":false,\"is_ultra_restricted\":false,\"who_can_share_contact_card\":\"EVERYONE\",\"profile\":{\"real_name\":\"User Name\",\"display_name\":\"User Name\",\"avatar_hash\":\"fxxxxxxxxxx\",\"real_name_normalized\":\"User Name\", [...] ,\"email\":\"user.name@example.com\",\"title\":\"\",\"phone\":\"\",\"skype\":\"\",\"status_text\":\"\",\"status_text_canonical\":\"\",\"status_emoji\":\"\",\"status_emoji_display_info\":[],\"status_expiration\":0,\"huddle_state\":\"default_unset\",\"huddle_state_expiration_ts\":0}}}",
"headers": {
"date": "Tue, 08 Jul 2025 07:54:18 GMT",
"server": "Apache",
"x-slack-req-id": "f7e8b2cda5f4c89c9eb6d9f0a1d6559e",
"x-content-type-options": "nosniff",
"x-xss-protection": "0",
"pragma": "no-cache",
"cache-control": "private, no-cache, no-store, must-revalidate",
"expires": "Sat, 26 Jul 1997 05:00:00 GMT",
"content-type": "application/json; charset=utf-8",
"x-accepted-oauth-scopes": "users:read",
"x-oauth-scopes": "app_mentions:read,chat:write,channels:read,channels:history,mpim:history,reactions:read,users:read,incoming-webhook,commands,groups:history,im:history,im:read,mpim:read,files:read,users:read.email",
"access-control-expose-headers": "x-slack-req-id, retry-after",
"access-control-allow-headers": "slack-route, x-slack-version-ts, x-b3-traceid, x-b3-spanid, x-b3-parentspanid, x-b3-sampled, x-b3-flags",
"strict-transport-security": "max-age=31536000; includeSubDomains; preload",
"referrer-policy": "no-referrer",
"x-slack-unique-id": "aGzOqj-BrZ84UCBqUQU1fAAAEDA",
"x-slack-backend": "r",
"access-control-allow-origin": "*",
"via": "1.1 slack-prod.tinyspeck.com, envoy-www-iad-efpiixvu,envoy-edge-iad-xitkllze",
"vary": "Accept-Encoding",
"content-encoding": "br",
"content-length": "561",
"x-envoy-attempt-count": "1",
"x-envoy-upstream-service-time": "20",
"x-backend": "main_normal main_canary_with_overflow main_control_with_overflow",
"x-server": "slack-www-hhvm-main-iad-ncit",
"x-slack-shared-secret-outcome": "no-match",
"x-edge-backend": "envoy-www",
"x-geoname-id": "notfound",
"x-slack-edge-shared-secret-outcome": "no-match"
},
"files": []
}ほしい情報は「レスポンス→ bodyを一回JSONにしたもの→user→profile→email」に入っているので、emailを抽出するためのコードを書く必要があります。難しいコードではないですが、毎回書くのが面倒くさいです。ここでDifyのParameter Extractorを使います:
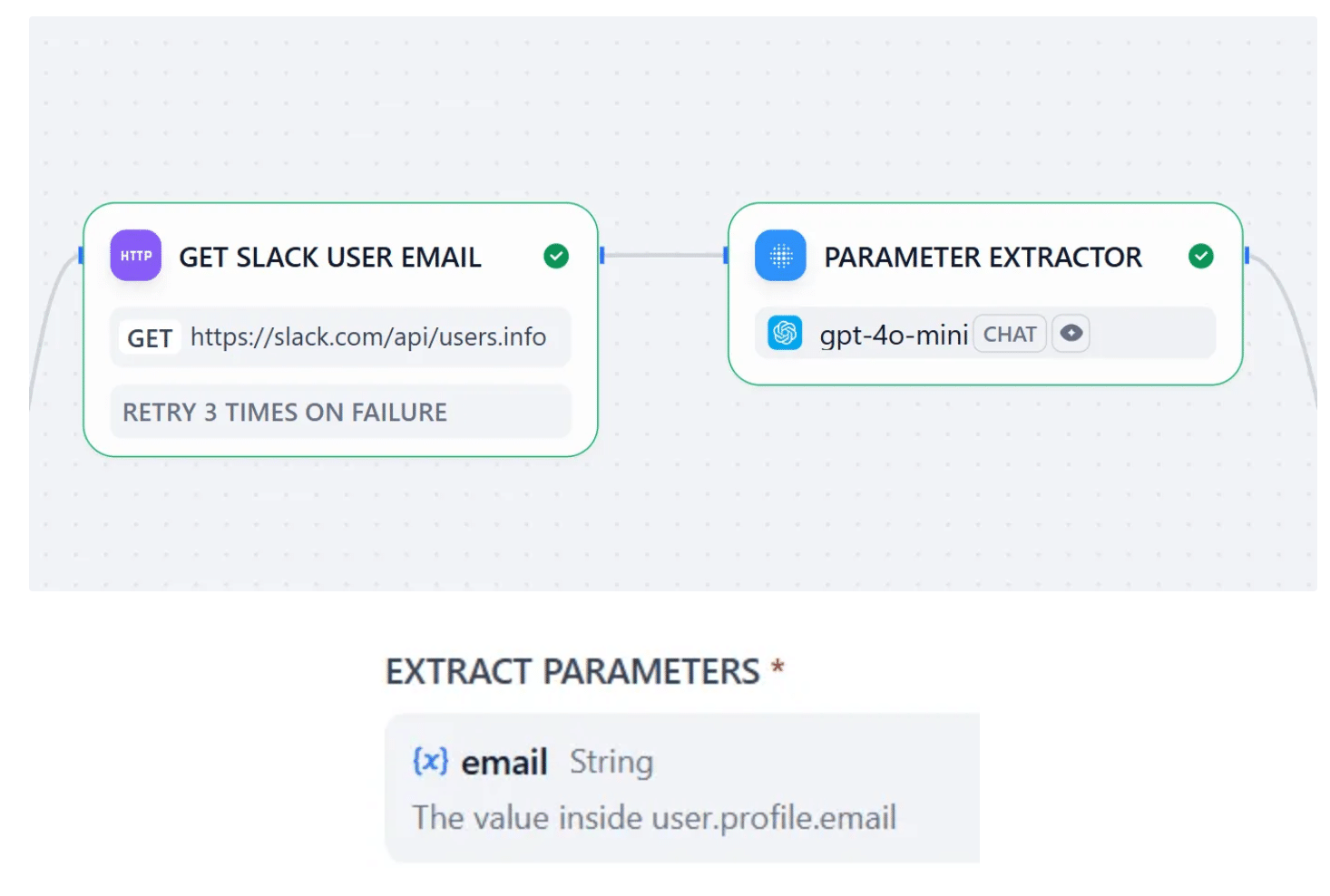
Parameter Extractorをつないで、画像のように「何を探すが」を書くだけです。これをやるだけで
{
"__is_success": 1,
"__reason": null,
"email": "user.name@example.com"
}が出てくるので、これ以降のノードでは[Parameter Extractorの名前].emailで参照できてらくらくです。
Ran:Difyってやはりすごいですねー そんな中で、🐜さんが工夫した点を一つ代表的な例をご紹介ください。
🐜さん:パラメータを抽出するときの指示は割と工夫しましたね。
1つの出力から1つのパラメータを抽出するときに上記のParameter Extractorがとても使いやすいです。しかし、より複雑なことをしたいときはLLMに様々な情報をまとめて渡して処理をしてもらいたいケースが多いです。例えば、今回は「プロジェクト一覧」、「ユーザー一覧」、「現在時刻」をユーザープロンプトと合わせて、Notionのページ作成時に使う情報を一気に考えさせたいとします。ノードは以下のようになります(簡潔にするために一部つなぎ目を消しています):
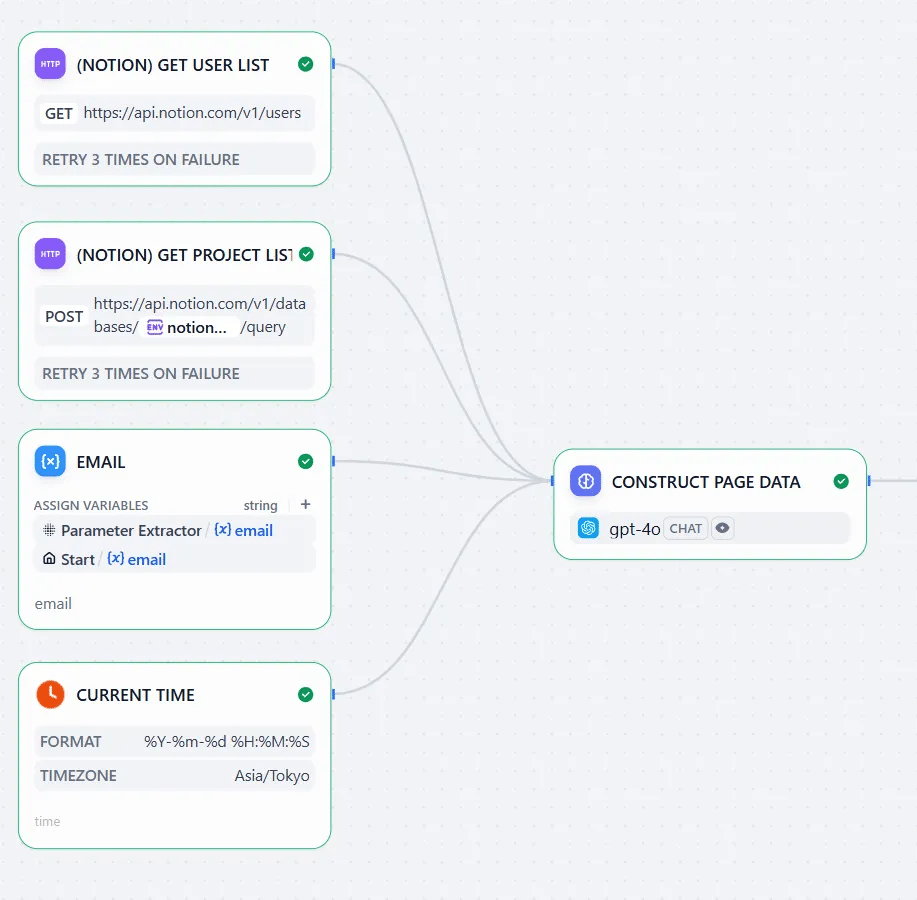
基本的に、LLMに情報を渡しすぎたり、指示が多いのに曖昧過ぎたりすると混乱しやすく、期待している回答を得ることが難しくなります。その混乱を抑えるために鍵になるテクニックが2点になります:
- 渡す情報それぞれの意味を教えてあげる(ここではそれぞれを別のassistantメッセージに分けて説明文を簡潔につけています)
- 出力をstructured_outputにして型を固定させ、それぞれのパラメータを細かく説明する
特に2点目で出力が大きく変わります。例えば稼働時間の「hours」において、
- 「開始時間か終了時間が指定されていないときはおそらくユーザーが時間を直で書いているので読んでみて」と指示する
- 「例:1, 1.5」と書くとLLMはむしろ1と1.5しか使うことができないと思い込むので「30分と言われたら0.5ずつ増やして」とだけ伝えてあとは計算させる
など、試行錯誤を繰り返しながら想定内の結果になるまでテストを続けます。
さいごに
このように、弊社では、DifyやNotion、Slackを用いて社内のワークフローの効率化に取り組んでいます。今後も、社内の効率化事例や便利AIツールの情報、業務効率化AIエージェントなどの情報や、Dify等のAIツールの開発情報をお届けしていきます。
また、自社でも社内効率化ツールを開発したい、新規事業を作りたい、といったご相談があれば、お気軽にPolyscape お問い合わせまでご相談ください。
